Zielona transformacja jako klucz do długoterminowego sukcesu
Zrównoważony rozwój jako strategiczna przewaga biznesowa. Dlaczego myślenie długoterminowe otwiera drzwi do większej konkurencyjności i nowych rynków.
 Autor:
Autor:W tym artykule opowiedziemy Wam o szczegółach oprogramowania Docker i podstawowych komendach do jego obsługi. Omówimy także strukturę pokazanego w poprzednim artykule pliku Dockerfile oraz powiemy czym są właściwie wolumeny i do czego są one używane. Zapraszamy do lektury!
Komendy pliku Dockerfile
W poprzednim artykule pojawił się przykład pliku Dockerfile, ale nie omawialiśmy co konkretnie robią poszczególne polecenia.
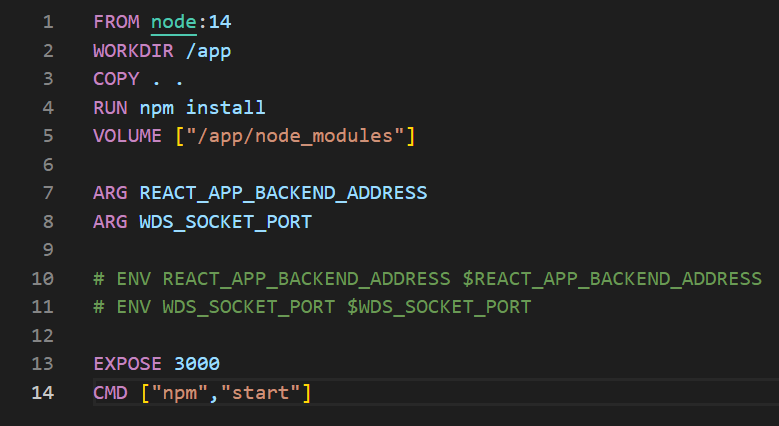 Rysunek 1: Przykładowy Dockerfile uruchamiający aplikację w JavaScript
Rysunek 1: Przykładowy Dockerfile uruchamiający aplikację w JavaScript
FROM – Wskazujemy obraz bazowy na podstawie którego chcemy zbudować nasz. Jeśli nie jest z’cachowany w lokalnym repozytorium, to zostanie ściągnięty z DockerHub’a.
WORKDIR – Zmienia ścieżkę na której pracujemy wewnątrz kontenera (domyślnie jest to “/” ). Jeśli folder nie istnieje (tak jak tu folder /app), to zostaje utworzony. Używanie tej komendy, a następnie odwołania w sposób względny są dobrą praktyką w przeciwieństwie do podawania konkretnych ścieżek bezwzględnych.
COPY – określamy które pliki mają być skopiowane z zewnątrz (z naszego komputera), do obrazu. Symbol “.” oznacza folder w którym obecnie pracujemy.
Składnia:
COPY <SRC_FROM_HOST> <DST_INTO_IMAGE>
Dopuszczalne jest także:
COPY . .
EXPOSE – Komenda wbrew powszechnemu przekonaniu nie udostępnia portu na zewnątrz kontenera (do host systemu), ani nie udostępnia portu dla innych kontenerów (domyślnie jest taki port dostępny). Komenda ta służy głównie dokumentacji, choć polecenie ‘docker run’ z flagą -P udostępnia port wyspecyfikowany w EXPOSE do host systemu.
RUN – Komenda uruchamiająca polecenie w trakcie budowania obrazu. Tutaj w przypadku “RUN npm install..” instalujemy zależności, które powinny być dołączone razem z obrazem PRZED uruchomieniem samego kontenera.
CMD – Komenda, która zostanie wykonana dopiero przy starcie kontenera. Tutaj za pomocą polecenia “npm start” uruchamiamy aplikację i należy to zrobić podczas startu. Jeśli użyjemy “RUN npm start” w pliku Dockerfile, to nasz obraz się nie zbuild’uje.
Może istnieć tylko jedno polecenie CMD na każdy Dockerfile. Jeśli nie wyspecyfikujesz CMD, to Docker spróbuje znaleźć CMD obrazu nadrzędnego (tego z FROM) i jeśli nie znajdzie to wyrzuci błąd.
Z użyciem tych podstawowych komend jesteśmy w stanie postawić najprostszą aplikację w dowolnej technologii wspieranej przez Docker’a. Większe i bardziej skomplikowane aplikacje często wymagają większej ilości poleceń, w tym używania zmiennych środowiskowych czy argumentów.
Budowanie obrazu
Aby zbudować obraz należy wykonać polecenie “ docker build -t <nazwa_obrazu> . “ w folderze w którym napisaliśmy plik Dockerfile. Jeśli wszystkie polecenia oraz kod, który chcemy uruchomić są napisane poprawnie powinien powstać obraz.
Rysunek 2. Proces budowania obrazu otagowanego jako “app”.
Aby zobaczyć zbudowany obraz możemy wykorzystać polecenie “docker images”, a jeśli chcemy dokładnie zbadać zawartość obrazu możemy wykorzystać polecenie “docker inspect”, które pokazuje nam nadbudowane warstwy odpowiadające kolejnym poleceniom w pliku Dockerfile. Mechanizm wyliczania skrótu i oznaczania nimi warstw w celu cache’owania i optymalizacji wykorzystania pamięci.

Rysunek 3. Output komendy docker image inspect pokazującej kolejne warstwy wynikające z komend Dockerfile.
W kontekście kolejnych warstw i poleceń w pliku Dockerfile warto powiedzieć o tym jak efektywnie korzystać z cache’a Docker’a. Komendy, które mogą często zmieniać hash obrazu, jak np. COPY . . (kopiowanie kodu), umieszczamy tak późno jak to możliwe w pliku Dockerfile, aby zmiana kodu nie implikowała zmiany hashu warstw, które są stałe. Jeśli umieścisz COPY na początku, to wtedy takie komendy jak apt update lub apt install będą wykonywane od nowa z każdą zmianą kodu.
Udostępnianie obrazu
Należy zadać sobie pytanie w jaki sposób właściwie dystrybuujemy naszą aplikację do innych. Odpowiedź wcale nie jest oczywista ponieważ możemy zrobić to na dwa sposoby. Pierwszy to poprzez udostępnienie pliku Dockerfile oraz zależności (kodu), które umieszczane są w obrazie. Drugi natomiast to wykorzystanie repozytorium obrazów do dystrybucji aplikacji. W Dockerz’e, tak jak choćby w systemie kontroli wersji, występuje pojęcie repozytorium lokalnego jak i zdalnego. Dockerhub to oficjalne publiczna wersja tego mechanizmu w którym można przechowywać stworzone przez siebie obrazy aplikacji. Można to przyrównać do systemu Github tylko dla obrazów Docker.
Rysunek 4. Oficjalny obraz bazy danych MySQL. Źródło: Dockerhub.
Na DockerHubie można znaleźć np. takie obrazy jak mysql, ubuntu, alpine, node czy prestashop. Obrazy te to zwykle jakiś lekki Linux z zainstalowaną, zintegrowaną z systemem aplikacją jak np. mysql czy interpreter node.
Rodzaje danych
Dane, których używamy w naszych aplikacjach, możemy sklasyfikować na kilka sposobów. W kontekście Docker’a warto zrobić to w następujący sposób:
Wolumeny
Docker Volume to system plików całkowicie zarządzany przez platformę Docker, istniejący jako normalny plik lub katalog na hoście, na którym dane są utrwalane.
Celem korzystania z wolumenów Docker jest utrwalenie danych poza kontenerem, aby można było tworzyć kopie zapasowe i przenosić pliki pomiędzy systemem kontenerem a hostem.
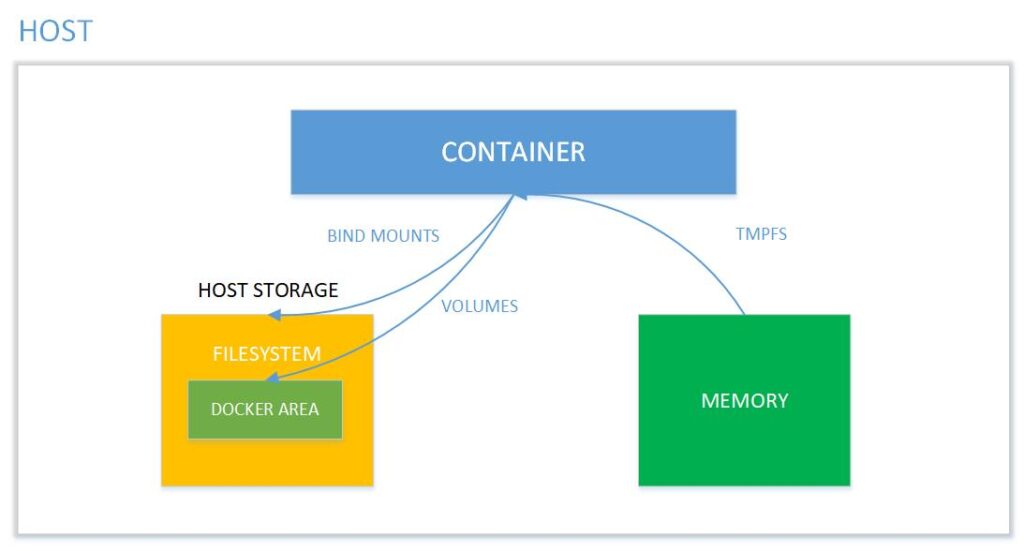
Rysunek 5. Mapowanie pamięci pomiędzy kontenerem, a systemem hosta. Źródło: binarymaps.
Podział wolumenów:
Podsumowanie
Udało nam się dzisiaj poznać podstawowe komendy Dockerfile, dowiedzieć jakie są sposoby na dystrybucję naszej konteneryzowanej aplikacji, a także jakie rodzaje danych i wolumenów można wyróżnić w Dockerze. W kolejnym artykule opowiemy więcej o mount bind oraz problemach jakie można napotkać w tym kontekście. Powiemy także czym są zmienne środowiskowe czy plik .dockerignore.
Źródła:
https://binarymaps.com/docker-storage/
https://pl.wikipedia.org/wiki/Wirtualizacja
https://www.atlassian.com/pl/microservices/cloud-computing/containers-vs-vms
https://www.ibm.com/cloud/blog/containers-vs-vms

Zielona transformacja jako klucz do długoterminowego sukcesu
Zrównoważony rozwój jako strategiczna przewaga biznesowa. Dlaczego myślenie długoterminowe otwiera drzwi do większej konkurencyjności i nowych rynków.
Zielone IT

„AI dla lepszej przyszłości” – jak INNOKREA inspirowała podczas CEATEC Japan
To był mój pierwszy raz w Japonii. Spodziewałem się hałasu i nadmiaru technologii. Zamiast tego zobaczyłem spokojne twarze, precyzyjne rozmowy i cichą determinację.
InnowacjaSztuczna InteligencjaWydarzenia

INNOKREA na EDAG Smart Industry Summit, Fulda 2025 – i co to było za wydarzenie!
Już jadąc do Fuldy byliśmy w świetnych humorach😊, tak jakby wszystko miało pójść po naszej myśli. Samolot był super punktualny, bagaż dostaliśmy po kilku minutach czekania jako pierwsi pasażerowie
InnowacjaSztuczna InteligencjaWydarzenia