Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
 Autor:
Autor:Czy zastanawiacie się jakie kłopoty mogą spotkać początkującego użytkownika Dockera? Czym są Bind Mounts i jakie zagrożenia niesie ich nieprawidłowe używanie? Jak Jak sobie radzić z tymi problemami, które pojawią się w Dockerze? Zachęcamy jako Innokrea do przeczytania i poszerzenia swojej wiedzy.
Bind Mount
Bind Mount są elementami systemu Docker zarządzanymi przez użytkownika Docker. Rozwiązują one inny problem niż wolumeny. Jeśli chcesz zmieniać kod i widzieć zmiany w swojej aplikacji musisz za każdym razem budować obraz od nowa. Odpowiednie użycie Bind Mounts sprawia, że zmiany są widoczne od razu w działającym kontenerze. Idea jest taka, by podłączyć konkretny folder z naszym kodem na host maszynie do kontenera tak, aby mieć do niego dostęp zarówno z kontenera (aby aplikacja mogła działać) jak i hosta (aby móc edytować kod). Zmiany w kodzie będą widoczne od razu.
O ile wolumeny są po to, żeby dane były persystentne, to Bind Mounts są po to, aby dane były edytowalne.
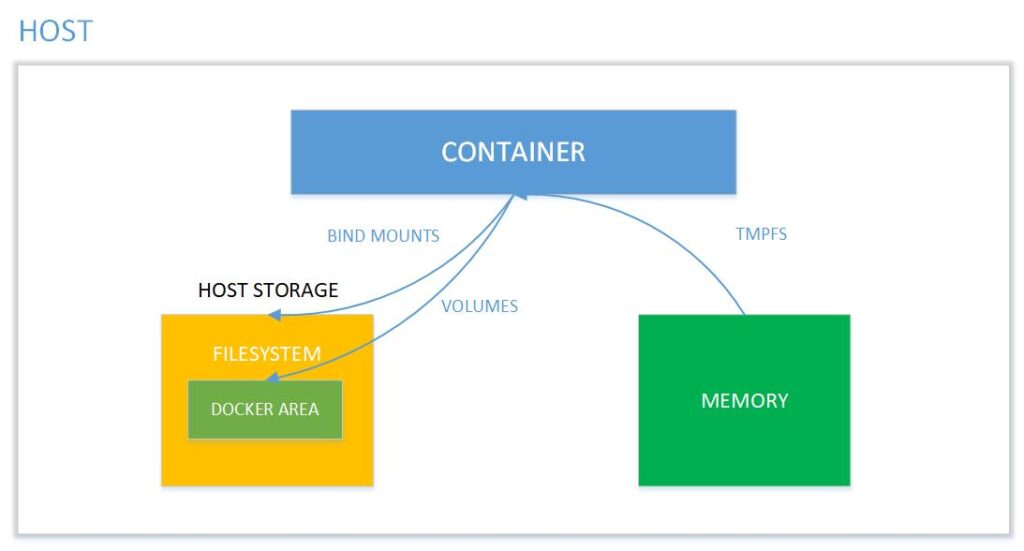
Rysunek 1: Mapowanie pamięci pomiędzy kontenerem, a systemem hosta. Źródło: binarymaps
Należy zwrócić uwagę na to jak na rysunku zaznaczone jest bind mounts. Różnica między wolumenem, a bind mount jest taka, że wolumen jest w pełni zarządzany przez Dockera. Bind mount natomiast ma bezpośredni dostęp do systemu plików hosta.
Live reload kodu
Jak wspominaliśmy, mechanizm bind mount pozwala na podmianę plików z poziomu hosta w działającym kontenerze bez potrzeby ponownego budowania obrazu. Czy oznacza to, że np. programując aplikację jesteśmy w stanie od razu zobaczyć zmiany, kiedy edytujemy dany plik? Otóż, to zależy od technologii w jakiej programujemy. Jeśli wykorzystujemy np. do naszego programu interpreter Python rozwijając aplikację z użyciem framework’a Flask, to jest to jak najbardziej możliwe, o ile tylko nie zrobimy błędów w składni języka. Jeśli jakiekolwiek błędy wystąpią aplikacja może się wyłączyć i będzie to wymagać resetu kontenera. Czasem, jak choćby w przypadku użycia framework’a React.js, pliki nie są dynamicznie ładowane do pamięci programu przy edycji i trzeba zainstalować zewnętrzną wtyczkę (np. nodemon), która będzie wykrywać zmiany plików i ponownie interpretować edytowany kod. Sprawa staje się jeszcze bardziej skomplikowana w przypadku języków częściowo kompilowanych jak np. Java. Możliwe jest ustawienie ponownej kompilacji po edycji plików, ale z naszego doświadczenia wynika, że jest to bardziej problematyczne.
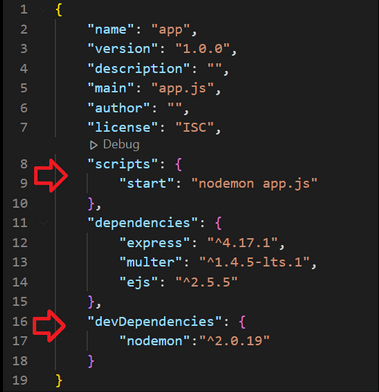
Rysunek 2: Wyspecyfikowanie dodatkowej zależności nodemon, pozwalającej na dynamiczne przeładowanie kodu w działającym kontenerze w aplikacji React.js
Inne problemy
Innym, dość mało oczekiwanym problemem jest ten w którym podmieniamy sobie przypadkowo potrzebne w kontenerze pliki. Wyjaśnijmy to na przykładzie framework’ów Flask oraz React.js. Jeśli nasza aplikacja wymaga zależności to w przypadku Python’a używamy narzędzia pip oraz pliku requirements.txt do ich zainstalowania podczas budowania obrazu. Domontowanie bind mount nie zmienia nic w zainstalowanych zależnościach, ze względu na to, że pliki źródłowe kodu i zależności znajdują się w różnych miejscach. W przypadku React.js i node’a natomiast używamy narzędzia npm i pliku package.json. Zależności instalowane są w folderze w którym jest plik package.json i przeważnie kod. Mapowanie za pomocą bind mount nadpisuje więc cały folder na ten znajdujący się na hoście, co oznacza, że po podmontowaniu nasze moduły znikną jeśli nie są zainstalowane w folderze na hoście. Aplikacja zacznie zwracać błędy o niezainstalowanych modułach.
Aby naprawić problem nadpisywanych zależności należy po prostu zrobić, w miejscu którego nie chcemy nadpisać w kontenerze, wolumen – najlepiej anonimowy. Można go wyspecyfikować z poziomu pliku Dockerfile, lub podać podczas uruchamiania z użyciem komendy “docker run -v /app/node_modules”. Utworzenie wolumenu sprawia, że dany folder jest zarządzany przez Docker’a, a nie użytkownika. Folder ten nie będzie nadpisany przez bind mount.
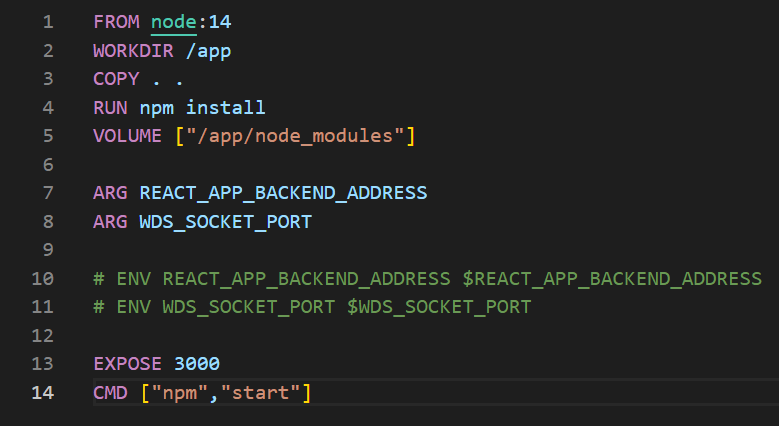 Rysunek 3: Zwróćmy uwagę na linię piątą chroniącą folder node_modules przed podmianą z pomocą mount bind
Rysunek 3: Zwróćmy uwagę na linię piątą chroniącą folder node_modules przed podmianą z pomocą mount bind
Poprawne stosowanie bind mounts nie jest sprawą trywialną i wymaga dokładnego zrozumienia tego co właściwie się dzieje. Ponieważ jeden folder hosta może być używany przez wiele kontenerów dobrą praktyką jest mapowanie w trybie :ro (read-only). Uniemożliwia to zapis przez kontener treści do systemu hostującego. Zapisywanie na system hosta powinno odbywać się poprzez wolumeny. Podsumowując warto robić tak, żeby modyfikacja kodu mogła nastąpić jedynie z poziomu systemu hosta, a jednocześnie umożliwić zapis niezbędnych przesłanych/wygenerowanych plików z kontenera do hosta poprzez wolumeny.
Zmienne środowiskowe
Na początku warto powiedzieć czym są zmienne środowiskowe. Są to zmienne w naszym systemie z których korzystają programy. Taka zmienna może wpływać na działanie procesów uruchamianych w systemie operacyjnym i może być pewnym mechanizmem komunikacji lub też przechowywać wartość w celu jej późniejszego wykorzystania. W Dockerze można takie zmienne specyfikować w pliku Dockerfile i nadawać ich domyślną wartość. Następnie podczas uruchomienia istnieje możliwość ich nadpisania z użyciem parametru -e.
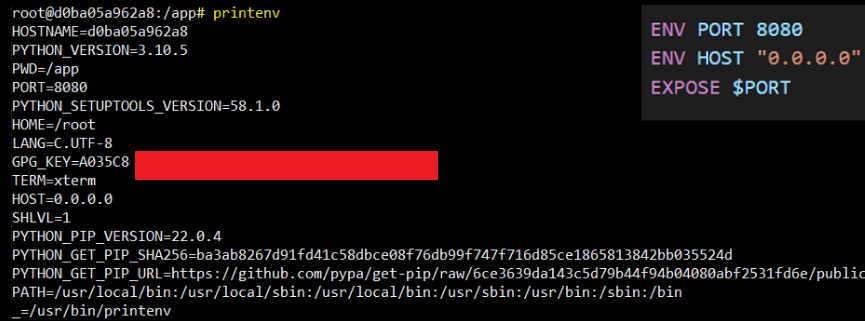
Rysunek 4: Przykładowe zmienne środowiskowe kontenera, obok zawartość pliku Dockerfile
Poprzez zastosowanie zmiennych środowiskowych jesteśmy w stanie uruchomić kontener parametryzując zmienne oznaczone jako ENV w Dockerfile bez przebudowywania obrazu podając parametry podczas uruchamiania kontenera (docker run). W ten sposób jesteśmy w stanie na przykład zmienić fragment wewnątrz kodu odpowiedzialny za to na jakim porcie działa aplikacja. Dodatkowo warto wspomnieć, że zmienne środowiskowe mogą mieć zastosowanie przy przekazywaniu do kontenera pewnych sekretnych danych jak np. klucze czy hasła. Nie należy takich rzeczy zaszywać w obrazie, ponieważ można je odzyskać z obrazu za pomocą komendy docker history <image-id>. Zaszywanie tajnych informacji jako zmienne środowiskowe też nie jest najlepszą praktyką z możliwych (sprawdź docker secret), jednak spotykaną w praktyce. Warto także używać pliku .env, który należy wyłączyć ze śledzenia przez system kontroli wersji, aby nie upublicznić takich sekretnych zmiennych do repozytorium, jeśli oczywiście uznajemy dane zmienne za tajne.
Plik .dockerignore
Do repozytorium naszej aplikacji powinno się także dodać plik “.dockerignore” w którym specyfikuje się pliki i foldery, których nie chcemy przenosić do wewnątrz obrazu pod wpływem instrukcji COPY . . w Dockerfile. Oczywiście możnaby też w Dockerfile specyfikować jedynie konkretne pliki i foldery, ale taki sposób z .dockerignore jest wygodniejszy. Generalnie plik .dockerignore powinien zawierać wszystkie pliki i foldery, które nie są niezbędne do działania naszej aplikacji np. “Dockerfile”, “.git”, “node-modules” lub są potencjalnie niebezpieczne jak token’y, klucze prywatne czy dane do logowania. Odnosząc to znanego dużej ilości osób systemu kontroli wersji GIT można to podsumować w ten sposób:
– Plik .gitignore w narzędziu GIT służy do wylistowania plików, które nie mają być śledzone podczas zmian w repozytorium.
– Plik .dockerignore umożliwia określenie listy plików lub katalogów, które Docker ma ignorować podczas procesu budowania.
Podsumowanie
Udało nam się dzisiaj omówić wszystkie najbardziej podstawowe zagadnienia Docker’a, których znajomość potrzebna jest początkującemu użytkownikowi. Zachęcamy szczególnie do analizy problemów przedstawionych w tym artykule oraz do zajrzenia do dwóch poprzednich artykułów na temat dockera (część 1 i część 2). W ostatnim odcinku z serii nt. dockera (część 4), opowiemy wam o docker-compose oraz podsumujemy i rozwiniemy aspekty związane z bezpieczeństwem kontenerów.
Źródła:
https://binarymaps.com/docker-storage/
https://pl.wikipedia.org/wiki/Wirtualizacja
https://www.atlassian.com/pl/microservices/cloud-computing/containers-vs-vms
https://www.ibm.com/cloud/blog/containers-vs-vms

Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
AdministracjaInnowacja
Helm – czyli jak uprościć zarządzanie w Kubernetes?
Warto o tym wiedzieć! Czym jest Helm, jak go używać i jak ułatwia on korzystanie z klastra Kubernetes?
AdministracjaInnowacja

INNOKREA na Greentech Festival 2025® – zdobyliśmy zielone serce Berlina!
Jak wygląda przyszłość zielonych technologii i jak nasza platforma wpisuje się w ideę recommerce? Relacjonujemy nasz udział w Greentech Festival w Berlinie – zobaczcie, co przywieźliśmy z tego inspirującego wydarzenia!
WydarzeniaZielone IT