Ekologiczne centra danych – jak wybrać dostawcę IT dbającego o planetę?
Przewodnik dla firm poszukujących partnerów IT korzystających z energooszczędnych rozwiązań
 Autor:
Autor:Dzisiaj jako Innokrea opowiemy Wam jeszcze więcej o superkomputerach. Jeśli interesują was stosowane w klastrach technologie, czy to jak chłodzi się gigantyczne superkomputery, to dzisiaj dowiecie się tego z naszego artykułu. Zapraszamy do lektury!
Pomiar mocy obliczeniowej
Należy zdać sobie pytanie jak zmierzyć prędkość superkomputera. Otóż wykorzystuje się w tym celu parametr określany jako FLOPS (Floating Point Operations Per Second). Jest to powszechnie wykorzystywana jednostka mocy obliczeniowej, inaczej liczba operacji zmiennoprzecinkowych, które komputer może wykonać na sekundę. Jest powszechnie używana do oceny wydajności superkomputerów, klastrów obliczeniowych czy na przykład kart graficznych.
Dylemat GPU vs CPU
Istnieją różne podejścia jeśli chodzi o budowę superkomputerów. Zwykle do CPU każdy komputer ma swoje GPU, które wspomaga obliczenia, choć nie zawsze. GPU computing to wykorzystanie GPU (procesora graficznego) jako koprocesora w celu przyspieszenia CPU w obliczeniach.
Układy GPU najlepiej nadają się do powtarzalnych i wysoce równoległych zadań obliczeniowych tam gdzie obliczenia nie zależą od siebie np. tekstury w grach (przy ruchu kamery przestawiamy każdy obiekt równolegle o pewien wektor). Poza renderowaniem wideo, układy GPU są wykorzystywane w uczeniu maszynowym, symulacjach finansowych oraz w wielu innych rodzajach obliczeń naukowych.
GPU przyspiesza więc aplikacje działające na procesorze, odciążając niektóre części kodu wymagające dużej mocy obliczeniowej i czasu. Reszta aplikacji nadal działa na procesorze. Z punktu widzenia użytkownika aplikacja działa szybciej, ponieważ wykorzystuje masowo równoległą moc przetwarzania GPU do zwiększenia wydajności. Jest to znane jako przetwarzanie hybrydowe.
Warto zaznaczyć, że procesor składa się zwykle z czterech do ośmiu rdzeni procesora, podczas gdy GPU składa się z setek mniejszych rdzeni. Pamiętajmy również, że równoległa architektura GPU zapewnia rzeczywiście wysoką wydajność obliczeniową, ale tylko w przypadku gdy dany problem daje się z definicji podzielić na równolegle rozwiązywalne podproblemy. Problem tez powinien być odpowiednio duży, ponieważ rozpraszanie niewielkich problemów może skutkować paradoksalnie zwiększeniem czasu wykonywania ze względu na narzut komunikacyjny.
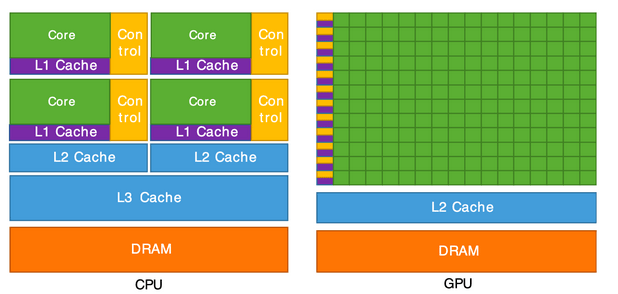
Rysunek 1: Porównanie CPU vs GPU – źródło Cornell University.
Dostępne technologie
Istnieje wiele technologii pozwalających na korzystanie z dodatkowej mocy GPU czy węzłów superkomputera. My jednak wspomnimy o dwóch – CUDA oraz MPI.
CUDA to platforma obliczeniowa stworzony przez firmę NVIDIA. Z ponad 20 milionami pobrań do tej pory, CUDA pomaga programistom przyspieszyć ich aplikacje, wykorzystując moc GPU. Umożliwia zatem przetwarzanie równoległe, dzieląc zadanie programowe na tysiące mniejszych „wątków” wykonywanych niezależnie Procesor jest oczywiście również zaangażowany w obliczenia, ale część zadań może delegować do GPU poprzez przekazanie instrukcji. Gdy GPU wykona otrzymaną pracę wyniki są przekazywane z powrotem do procesora w celu wykorzystania przez aplikację. CUDA jest używana choćby w Machine Learning w różnych dziedzinach jak przetwarzanie języka naturalnego czy rozpoznawanie obrazów.
MPI to natomiast standard programowania rozproszonych komputerów, który umożliwia współpracę wielu procesów w rozwiązywaniu problemów. Zapewnia zestaw funkcji bibliotecznych oraz składni do przekazywania komunikatów między procesami w programach równoległych, co czyni go popularnym narzędziem w zastosowaniach wysokiej wydajności np. w superkomputerach czy klastrach. MPI został stworzony z trzema głównymi celami: zapewnieniem wysokiej jakości, skalowalności i przenośności. Jest on obecnie powszechnie używanym modelem w klastrach komputerowych oraz superkomputerach. Pierwsza wersja standardu została opublikowana w maju 1994 roku. Standard MPI jest zazwyczaj implementowany jako biblioteki, które można wykorzystywać w programach tworzonych w różnych językach programowania, takich jak C, C++, Ada czy Fortran. Istnieje także możliwość wykorzystania go w Pythonie (PyMPI).

Rysunek 2: Fragment kodu C wykorzystującego MPI
Chłodzenie centrum danych
Istnieją dwa główne sposoby chłodzenia centrów danych czy superkomputerów. Są to:
Podczas budowy centrum danych należy także wziąć pod uwagę odpowiedni ustawienie szaf RACK, tak aby tworzyć gorące i zimne alejki. Dzięki temu odprowadzanie powietrza jest zrealizowane w sposób efektywny.

Rysunek 3: Wizualizacja odprowadzania ciepła z centrum danych, źródło: 42u.com

Rysunek 4: Zdjęcie pokazujące chłodzenie cieczą w wysokowydajnym systemie, źródło CoolIT Systems
W przypadku największych na świecie superkomputerów, które produkują ogromne ilości ciepła, potrzebne są równie gigantyczne zbiorniki wody do chłodzenia. Mają one pojemność liczoną w setkach tysięcy lub nawet milionach litrów. Zwykle są one umieszczone w specjalnie zaprojektowanych pomieszczeniach lub poza budynkiem. Występują tam takie urządzenia wspomagające jak pompy do odprowadzania ciepła oraz chłodnice. Całość jest oczywiście wypełniona gamą czujników monitorujących stan i pracę całego systemu, a także w systemy alarmowe, które ostrzegają w przypadku awarii lub nieprawidłowej pracy.

Rysunek 5: Chłodzenie superkomputera Stampede w Texasie, 3,8 miliona litrów wody, źródło: Quora.
Mamy nadzieję, że ten artykuł był dla Was interesujący. Po więcej zapraszamy do kolejnego artykułu, gdzie zamiast o aspektach programowych czy konstrukcyjnych opowiemy o sieciach w superkomputerach, które budowane są nieco inaczej niż standardowe sieci korporacyjne, a nawet inaczej niż centra danych.
Źródła:

Ekologiczne centra danych – jak wybrać dostawcę IT dbającego o planetę?
Przewodnik dla firm poszukujących partnerów IT korzystających z energooszczędnych rozwiązań
Zielone IT

Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
AdministracjaInnowacja
Helm – czyli jak uprościć zarządzanie w Kubernetes?
Warto o tym wiedzieć! Czym jest Helm, jak go używać i jak ułatwia on korzystanie z klastra Kubernetes?
AdministracjaInnowacja