10 korzyści z dedykowanego oprogramowania dla Twojej firmy – mniej zasobów, większa wydajność
Dedykowane oprogramowanie to inwestycja, która zwiększa wydajność firmy, minimalizując zużycie zasobów IT i wspierając strategię zrównoważonego rozwoju.
 Autor:
Autor:Dzisiejszym artykułem kończymy serię o kryptografii i zaczynamy cykl wpisów dotyczących uczenia maszynowego – dziedziny rozwijającej się obecnie w niesamowitym tempie, która przenika praktycznie do wszystkich sektorów gospodarki, a także samej informatyki. Co więcej – zaryzykować można stwierdzeniem, że dzisiaj wszystkie najbardziej zaawansowane systemy informatyczne wspierane są rozwiązaniami z gałęzi nauki jaką jest uczenie maszynowe.
Trzeba jasno powiedzieć – choć dziedzina oferuje ogromne możliwości zastosowań i nierzadko pomaga niewiarygodnie ułatwić firmom czy badaczom pracę, to zanim jednak rzucimy się w wir śmiałego wprowadzania technologii ML (ang. Machine Learning) do biznesu, należy się poważnie zastanowić – przeanalizować zasoby finansowe, kadrowe oraz techniczne firmy – bowiem czasami użycie uczenia maszynowego nie jest najlepszym (a nawet w ogóle opłacalnym) wyborem. Dlaczego? Spróbujemy odpowiedzieć na to pytanie, jednocześnie wprowadzając parę charakterystyk tego podejścia oraz nadać na nie całościowy ogląd, nim zaczniemy na poważnie zagłębiać się w temat.
Wiele powszechnie stosowanych dziś technik uczenia maszynowego wymaga na start dużych zbiorów próbek o dobrej jakości. Niekiedy już samo to może stanowić spory problem – na przykład w sytuacji, w której mamy do czynienia z danymi wrażliwymi, do których dostęp jest ograniczony. Czasem oczywiście samo zebranie np. setek tysięcy zdjęć zawierających ludzkie twarze może nie być problemem – nadal jednak większość popularnych dziś metod, zaliczanych do tzw. uczenia nadzorowanego (ang. supervised learning) – takich jak sieci neuronowe czy drzewa decyzyjne – dodatkowo potrzebują do działania oznaczeń tych posiadanych danych, czyli pewnych informacji o próbkach, które zazwyczaj są już znacznie trudniejsze, bardziej czasochłonne i kosztowne do uzyskania. Przykładowo – sieć neuronowa, która rozpoznawać ma ze zdjęcia kontury twarzy, wymaga w procesie uczenia (treningu) przedstawienia jej wielu – tysięcy, dziesiątek tysięcy, a może nawet setek tysięcy (zależnie od rodzaju i skomplikowania architektury, a także jakości danych treningowych na wejściu) – obrazów, na których takie twarze zostały już rozpoznane, a informacje o obszarze zajmowanym przez nie w jakiś sposób zapisane w powiązaniu z tym plikiem. O sposobach zapisu takich danych powstać by mógł kolejny artykuł, pominiemy zatem zagłębianie się w takie szczegóły.

Rys. 1: Formatowanie oznaczeń danych (tu w formacie PASCAL VOC XML) na przykładzie zdjęcia psa. W przypadku etykietowania pewnych obszarów obrazów, dla każdej próbki należy przygotować taki dodatkowy plik opisujący zawartość. Źródło: Kurs ML 2023, Natalia Potrykus
Innym przykładem mogą być dane dla drzewa decyzyjnego, którego zadaniem ma być wyznaczenie zdolności kredytowej klienta banku. Algorytm taki, na podstawie informacji o kliencie (płeć, wiek, stan cywilny itp.), miałby wyznaczyć czy prawdopodobne jest, że aplikant spłaciłby kredyt bez problemu i na czas. Tutaj ponownie do skonstruowania wspomnianego modelu drzewa potrzebne byłyby archiwalne dane tysięcy klientów wraz z informacją, czy mieli oni problem z terminową spłatą. Dopiero na podstawie tych danych wytrenować można by model decyzyjny.
Oczywiście, znane są różne sposoby na radzenie sobie z problemem niewystarczającej ilości danych treningowych wraz z oznaczeniami, takie jak augmentacje, generowanie syntetyczne, uczenie pół-nadzorowane (wrócimy do tego), czy choćby uoskonalenie samego procesu treningu modeli do wybierania najbardziej reprezentatywnych próbek, zwane uczeniem aktywnym (ang. active learning) – co pozwala bieżąco oznaczać najistotniejsze dla procesu treningu dane (takie, których uzwględnienie wniesie jak najwięcej nowych informacji do modelu), niekiedy zupełnie pomijając oznaczanie próbek dla modelu nieznaczących – metody te jednak nie zawsze mogą przynieść pożądane rezultaty. Co więcej – do dnia pisania tego artykułu nieznane są żadne sposoby, które pozwoliłyby z zadowalającą pewnością stwierdzić słuszność wyboru któregoś z podejść lub zagwarantować ich określoną skuteczność.
Zdecydowanie łatwiej pozyskać jest dane do tzw. uczenia nienadzorowanego (ang. unsupervised learning), które przede wszystkim może służyć do grupowania danych, znajdywania między nimi podobieństw, wykrywania odchyleń, a na tej podstawie także np. uzupełniania danych brakujących. Tu etykiety próbek nie są nam potrzebne – podejście takie zazwyczaj jednak nie nadaje się do klasyfikacji czy rozwiązywania problemów decyzyjnych, a także ma istotne ograniczenia ze względu na to, że matematycznie zamodelowane metody nie zawsze są w stanie pokryć problemy ze świata rzeczywistego. Dobrze mogą sprawdzić się za to w przypadku konieczności syntetycznego uzupełnienia danych brakujących, grupowania danych, znajdowania między nimi podobieństw, czy zauważania pewnych anomalii.
Sprawa robi się jeszcze bardziej skomplikowana, jeżeli samodzielnie postanowimy skonfigurować parametry treningu i architektury modelu (przykładowo sztucznej sieci neuronowej). Oczywiście, dostępne są biblioteki języka Python, które oferują już zaimplementowane, a nawet niekiedy wstępnie wytrenowane modele (np. biblioteki PyTorch, Tensorflow) – nadal pozostaje jednak kwestia dobrania odpowiedniej architektury do naszego problemu, a także dostosowanie hiperparametrów (czyli charakterystyk modelu, które należy zadeklarować z góry, które nie podlegają zmianom wskutek treningu) – a tych zazwyczaj jest około kilkudziesięciu i każda z nich ma pewien wpływ na finałowe działanie sieci. Okazać się może, że nawet przy wyborze zaawansowanej architektury, która według publikacji naukowych osiąga na skomplikowanych zbiorach dokładność niemal idealną (niedaleką od 100%) – model będzie na naszych danych działał zauważalnie gorzej, jeżeli dobierzemy hiperparametry w sposób nieodpowiedni.
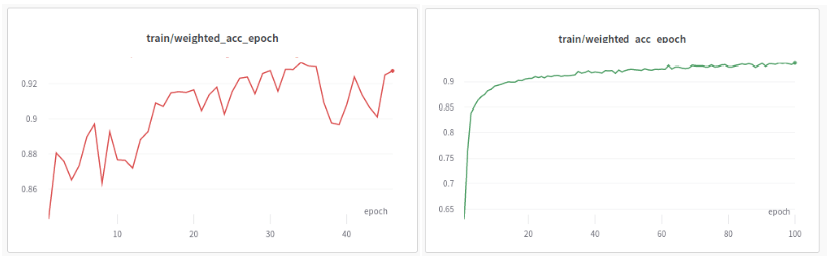
Rys. 2: Wykres z przebiegu treningu modelu o tej samej architekturze, ale inaczej dobranymi hiperparametrami. Źródło: Kurs ML 2023, Natalia Potrykus
Tutaj – niestety – ponownie nie ma gotowego remedium na rozwiązanie tego problemu, nie istnieje żaden konkretny “przepis” na konfigurację architektury czy charakterystyk treningu – umiejętność oraz pewna intuicja wyrabiane są dopiero wskutek doświadczenia (a nawet i wtedy niekóre sytuacje nadal sprawiać mogą niemałe wyzwanie). Jeżeli zatem nie mamy w zespole kadry doświadczonej w działaniu z modelami sztucznej inteligencji, zadanie wytworzenia dedykowanej sieci neuronowej najlepiej oddać w ręce specjalistów – dziś na rynku pojawia się coraz więcej firm oferujących korporacjom automatyzację ich procesów biznesowych.
Trening modelu sieci neuronowych, które są obecnie najchętniej wybieranym wsparciem automatyzacji w biznesie, jest zazwyczaj – po prostu – długi, jeżeli nie dysponujemy odpowiednimi zasobami sprzętowymi. Uczenie takie przeprowadza się na procesorach graficznych (GPU), które pozwalają na znacznie lepsze zrównoleglenie wykonywania wielu operacji mnożenia, niż jest to możliwe na CPU – a jako, że trening sieci to tak naprawdę wielokrotne mnożenie pewnych macierzy, to w ten sposób uzyskać możemy nawet kilkudziesięciokrotne przyspieszenie procesu! Oczywiście, wymaga to od firmy dostępu do wspomnianych jednostek technicznych – on premises lub w chmurze, co generować może dodatkowe koszty. Konieczna jest ponadto biegłość techniczna w delegowaniu zadań do przetwarzania rozproszonego – ponownie, współczesne frameworki do uczenia maszynowego zapewniają dobre wsparcie do angażowania zasobów procesorów graficznych – nadal jednak pozostaje konieczność umiejętnego zarządzania tymi zasobami, aby trening mógł rzeczywiście przebiec w sposób efektywny.
Załóżmy, że udało się nam wytrenować odpowiednią sieć i wdrożyć ją na produkcji. Czy to już koniec przejmowania się modułem ML w naszej firmie? Ależ skąd, to dopiero początek!
Sytuacja jest podobna do działania taśmy produkcyjnej w fabryce – pomyślne ustawienie nowego toru to prawdopodobnie rewelacyjna inwestycja, niemniej jednak wymaga stałej kontroli i konserwacji, by móc przez długi czas spełniać swoje zadanie – czasem może wystąpić konieczność wymiany jakiegoś elementu, niekiedy może trzeba będzie nasmarować łożyska, by zachować trwałość systemu, a kiedyś może nawet dostawić nowy komponent w miarę zmian potrzeb biznesowych? Z modelami ML sprawa jest analogiczna. Od momentu wdrożenia możemy z pewnością liczyć na pewien czas zadowalającego działania – będzie ono jednak bardzo zależne od wszelkich zmian w środowisku działania. Przyjrzyjmy się tej sytuacji na przykładzie: mamy sieć rozpoznającą na podstawie obrazu z kamery produkty wadliwe od tych poprawnie wykonanych. Początkowa dokładność modelu wynosi około 98% (czyli tyle produktów zostanie poprawnie sklasyfikowanych). W pewnym momencie jednak zachodzi konieczność wymiany oświetlenia na hali – i nagle dokładność rozpoznawania produktów spada do 65%! Z takimi sytuacjami trzeba się mierzyć, angażując sztuczną inteligencję w procesy biznesowe.
Rozwiązanie tego problemu jest dość proste – wystarczy dotrenować model na pewnym zbiorze świeżych danych (czyli w tym przypadku obrazów zebranych po zmianie lamp). Nadal jednak dane te trzeba zebrać, oznaczyć, procedurę treningu powtórzyć, a model wdrożyć w poprawionej wersji.
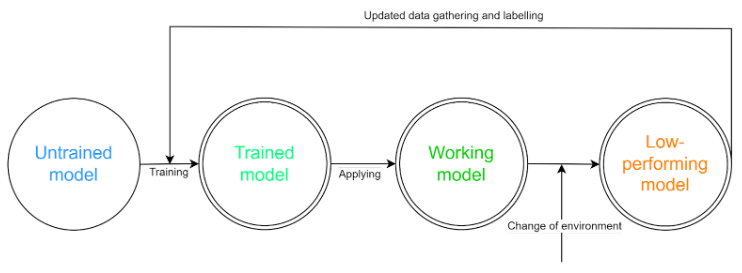
Rys. 3: Schemat cyklu działania modelu w środowisku produkcyjnym. Źródło: Kurs ML 2023, Natalia Potrykus
Niektóre firmy zajmujące się rozwojem uczenia maszynowego, świadome problemów, z którymi borykają się korporacje, oferują wraz z przystosowanymi modelami systemy do monitorowania jakości ich działania oraz rozpoznające różnice w napływających do nich danych – a niekiedy i wspomagany proces dotrenowania takich modeli w przypadku rozpoznania tzw. dryftu koncepcji, czyli właśnie zmian w przetwarzanych próbkach wejściowych.
Jak widzimy, choć automatyzacja procesów biznesowych to zjawisko coraz bardziej popularne (i zazwyczaj mocno opłacalne), to przeprowadzone musi zostać w sposób przemyślany i świadomy. Jednakże, przy odpowiednio przeprowadzonym procesie wdrażania rozwiązań ML do działania firmy, liczyć można na niesamowite korzyści – zarówno w wydajności, jak i w finansach. Dlatego też, warto poszerzać swoją wiedzę w tym temacie i być na bieżąco z obecnie stosowanymi rozwiązaniami. Po więcej ML-owych treści zapraszamy za tydzień!

10 korzyści z dedykowanego oprogramowania dla Twojej firmy – mniej zasobów, większa wydajność
Dedykowane oprogramowanie to inwestycja, która zwiększa wydajność firmy, minimalizując zużycie zasobów IT i wspierając strategię zrównoważonego rozwoju.
Zielone IT

Odpowiedzialne tworzenie oprogramowania: Jak zmniejszyć ślad węglowy aplikacji?
Praktyczne wskazówki jak programiści mogą aktywnie zmniejszyć emisję CO2 poprzez optymalizację kodu, infrastruktury i architektury aplikacji.
InnowacjaZielone IT

Zielone IT: Jak technologia może wspierać ochronę środowiska?
Wprowadzenie do idei zielonego IT (Green IT) – strategii, która łączy technologię z troską o planetę.
InnowacjaZielone IT