10 korzyści z dedykowanego oprogramowania dla Twojej firmy – mniej zasobów, większa wydajność
Dedykowane oprogramowanie to inwestycja, która zwiększa wydajność firmy, minimalizując zużycie zasobów IT i wspierając strategię zrównoważonego rozwoju.
 Autor:
Autor:Dzisiaj opowiemy Wam o tym, czym jest Kubernetes, o jego podstawowych możliwościach i dlaczego sam Docker to często za mało, aby prowadzić poważne środowisko produkcyjne. Jeśli nie masz jeszcze pełnej wiedzy o Dockerze, to polecamy nasze artykuły w tym temacie.
Jest on narzędziem orkiestracji kontenerów na dużą skalę niezależnie od dostawcy chmurowego. Pozwala na automatyczny deployment i zarządzanie kontenerami aplikacyjnymi. Jest narzędziem, które oferuje dużo więcej niż Docker. Można o nim myśleć jak o docker-compose z dodatkowymi funkcjami pozwalającym na pracę na wielu fizycznych maszynach. Warto także wspomnieć, że Kubernetes występuje w wielu wersjach jak np.:
Można wymienić ku temu kilka powodów jak np.:
Warto jednak wspomnieć, że istnieją także alternatywy do orkiestracji kontenerów jak np. AWS ECS (nie mylić z przedstawionym wyżej EKS) integrujące zarządzanie kontenerami z chmurą AWS. Porównanie Kubernetes do AWS ECS nie jest do końca trafne, ponieważ ECS opiera się na Docker Engine, a jego integracja z pozostałymi usługami AWS daje mu dodatkowe możliwości jak np. reset kontenera, autoscaling czy load-balancing, a także pozwala także na provisioning dodatkowych zasobów od AWS, co nie jest dostępne z poziomu Kubernetes. Wadą tego rozwiązania jest jednak zbytnie przywiązanie do dostawcy chmurowego, ponieważ konfiguracje yaml’owe dla ECS działają jedynie w ramach AWS, natomiast konfiguracje Kubernetes’owe działają niezależnie od dostawcy (o ile dostawca dostarcza odpowiednią wersję Kubernetes w ramach swojej infrastruktury).
Teraz, gdy już mamy pewną intuicję co do tego czym jest Kubernetes i jak różni się od Docker’a możemy przejść do omawiania podstawowych pojęć i klasyfikacji, których używamy rozmawiając o K8s.
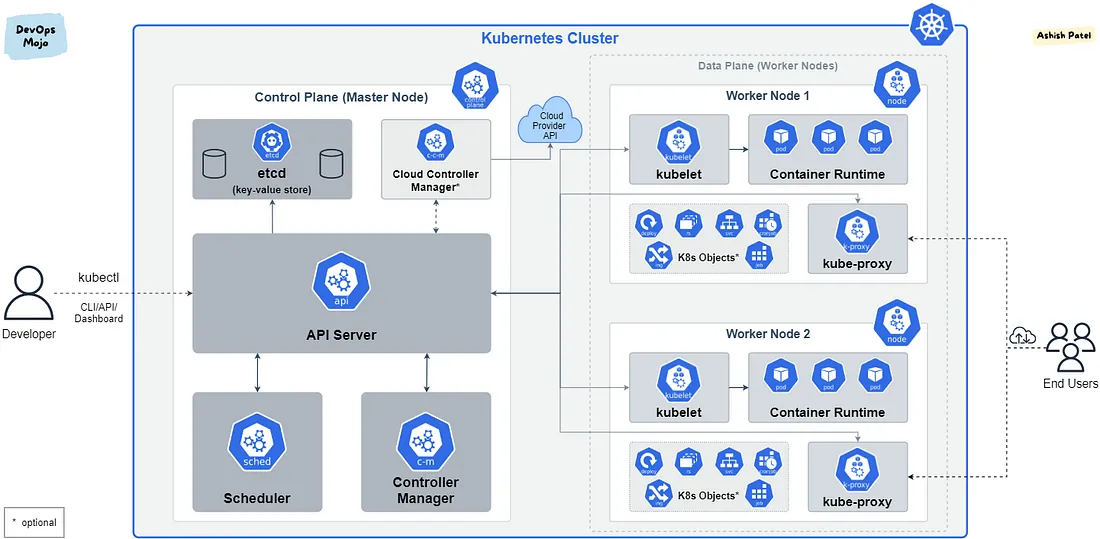
Rysunek 1 – elementy klastra Kubernetes, źródło: medium.com
Podstawowy podział jaki można wyróżnić w przypadku Kubernetes to:
Czasem w Internecie można spotkać określenie, że warstwa kontroli jest jak mózg, a warstwa danych jak reszta ciała i wydaje się to dość trafnym porównaniem. W skład tych warstw wchodzą różne komponenty, które możemy zaobserwować na powyższym rysunku. Można więc powiedzieć, że na klaster (tj. grupę współpracujących ze sobą komputerów) Kubernetes składa się z warstwy kontrolnej złożonej z master nodes wewnątrz których są różne procesy i usługi do zarządzania oraz z warstwy danych (data plane), które składa się zwykle z większej ilości tzw. worker nodes wewnątrz których znajdują się odpowiedni komponenty.
W skład warstwy kontroli wchodzą:
Natomiast na warstwę danych składają się między innymi takie elementy jak:
Warto także wspomnieć o tym za co Kubernetes jest odpowiedzialny, a za co administrator/deweloper go obsługujący. Stworzenie klastra, uruchomienie odpowiednich serwisów czy odpowiednich zasobów jak np. cloud storage z którego będzie korzystał Kubernetes to odpowiedzialność dewelopera. Natomiast zarządzanie podami, skalowanie, dążenie do osiągnięcia odpowiedniego stanu wytyczonego w konfiguracji to zadanie dla Kubernetes.
To już wszystko, o czym chcieliśmy Wam opowiedzieć w ramach wprowadzenia. Koniecznie zapoznajcie się z naszymi artykułami na temat dobrych praktyk w Dockerze oraz samego Dockera, jeśli chcecie zbudować solidne podstawy pod rozumienie Kubernetes. Do usłyszenia za tydzień!

10 korzyści z dedykowanego oprogramowania dla Twojej firmy – mniej zasobów, większa wydajność
Dedykowane oprogramowanie to inwestycja, która zwiększa wydajność firmy, minimalizując zużycie zasobów IT i wspierając strategię zrównoważonego rozwoju.
Zielone IT

Odpowiedzialne tworzenie oprogramowania: Jak zmniejszyć ślad węglowy aplikacji?
Praktyczne wskazówki jak programiści mogą aktywnie zmniejszyć emisję CO2 poprzez optymalizację kodu, infrastruktury i architektury aplikacji.
InnowacjaZielone IT

Zielone IT: Jak technologia może wspierać ochronę środowiska?
Wprowadzenie do idei zielonego IT (Green IT) – strategii, która łączy technologię z troską o planetę.
InnowacjaZielone IT