Ekologiczne centra danych – jak wybrać dostawcę IT dbającego o planetę?
Przewodnik dla firm poszukujących partnerów IT korzystających z energooszczędnych rozwiązań
 Autor:
Autor:Dzisiaj jako Innokrea opowiemy trochę o tym czym jest system rozproszony, jakie są jego właściwości, a także zobaczymy przykładową architekturę takiego systemu. Jeśli jesteście zainteresowani to zapraszamy do lektury!
Istnieją różne definicje czym jest właściwie system rozproszony od tych formalnych, naukowych, aż po te bardzo praktyczne. Jedne definicje wskazują na to, że rozproszony system to taki składający się z wielu komponentów lub programów umieszczonych na wielu węzłach czy komputerach. Inne natomiast kładą nacisk nie tylko na rozproszenie, ale także np. na to, że system rozproszony powinien jawić się użytkownikowi jako spójny system, a także na to, że występują różne płaszczyzny rozpraszania. Można jednak zidentyfikować pewne atrybuty, którymi cechuje się taki typ oprogramowania jak np.
Oczywiście nie wymieniliśmy tu wszystkich cech, ale te powyższe mogą Wam dodać trochę intuicji na temat takich systemów. Należy także powiedzieć, że nie każdy system rozproszony spełnia wszystkie te cechy.
Trzy najważniejsze płaszczyzny, na których można rozproszyć aplikacje, to: przetwarzanie, kontrola oraz dane. W zależności od naszych wymagań możemy manipulować stopniem rozproszenia w tych aspektach. Rozproszenie przetwarzania oznacza, że istnieją różne komputery połączone siecią przetwarzające pewne dane jak np. wyszukiwanie informacji czy mnożące macierze. Węzły otrzymują część pewnego zadania i usprawniają jego wykonanie jeśli równoległe przetwarzanie danych jest możliwe. Jeśli chodzi o dane to możemy tu mówić o ich replikacji lub o tzw. ‘data partitioning’ czyli przechowywaniu ich w różnych lokalizacjach. Przykładem są tutaj bazy danych, w których występują problemy z ich replikacją i synchronizacją w odpowiedni sposób rozwiązywane przez silniki bazodanowe. Jeśli chodzi o dystrybucję kontroli, to jest to przekazanie części kontroli do innego węzła komputera. Przykładem może być sieć P2P albo router, które podejmują decyzje routowania na podstawie lokalnych informacji. Kontrolna nad przekazywaniem wiadomości jest więc rozproszona. Spróbujmy przeanalizować architekturę klient-serwer, pod względem wyżej wymienionych kryteriów:
Można więc powiedzieć, że architektura klient-serwer sama w sobie nie jest ani szczególnie rozproszonym typem architektury, ani scentralizowanym. Powyższa analiza mogłaby zostać jednak mocno zmodyfikowana na potrzeby niektórych scenariuszy i nie byłoby w tym nic dziwnego. Podajemy tutaj ogólny zarys takiego systemu, a to jak mocne powinno być rozproszenie tak aby system był optymalny pozostaje w gestii projektującego.
Jednym z ważniejszych cech, które powinien posiadać system rozproszony, jest jak najlepsze ukrycie tego, że działa on na wielu węzłach. Dzięki temu korzystający z systemu użytkownik może nie martwiąc się o techniczne detale używać systemu jakby działał on na pojedynczej stacji. Istnieją różne rodzaje transparentności i możemy tu wyróżnić między innymi:
Zarówno w świecie naukowym jak i komercyjnym wykorzystuje się różne rodzaje rozproszenia ze względu na dużo większe możliwości skalowania horyzontalnego (takiego, w którym zwiększamy liczbę stacji w celu osiągnięcia większej mocy obliczeniowej). Skalowanie wertykalne ma swoje poważne ograniczenia i jest nieopłacalne powyżej pewnego poziomu. Klastry oraz superkomputery są wykorzystywane do zadań skomplikowanych obliczeniowo jak np. szkolenie modelu językowego czy modelowanie pogody. Istnieją specjalne platformy do rozpraszania zadań na wiele węzłów obliczeniowych jak np. Apache Hadoop.
W tym temacie polecamy serię artykułów dotyczącą superkomputerów: https://www.innokrea.pl/superkomputery/
Jeśli chodzi o dane, to można tu wymienić wszelkie rozwiązania służące do przechowywania wielkiej ilości danych jak np. Bigtable od Google czy DynamoDB od Amazona. Dane dystrybuowane są między wiele węzłów i dzięki temu można także przechowywać ogromne ich ilości w celu późniejszego wykonania na nich operacji lub wprost przeciwnie – zapisywać informacje powstałe w wyniku przetwarzania innych danych. Rozproszenie kontroli z kolei jest stosowane przy obsłudze systemów energetycznych czy środowiskowych, gdzie komponenty programowe są w stanie podejmować lokalne decyzje bez udziału centralnego serwera.
Do bardziej klasycznych przykładów systemów rozproszonych jakie znane są programistom należą także mikroserwisy stosowane choćby przez takie firmy jak Netflix.
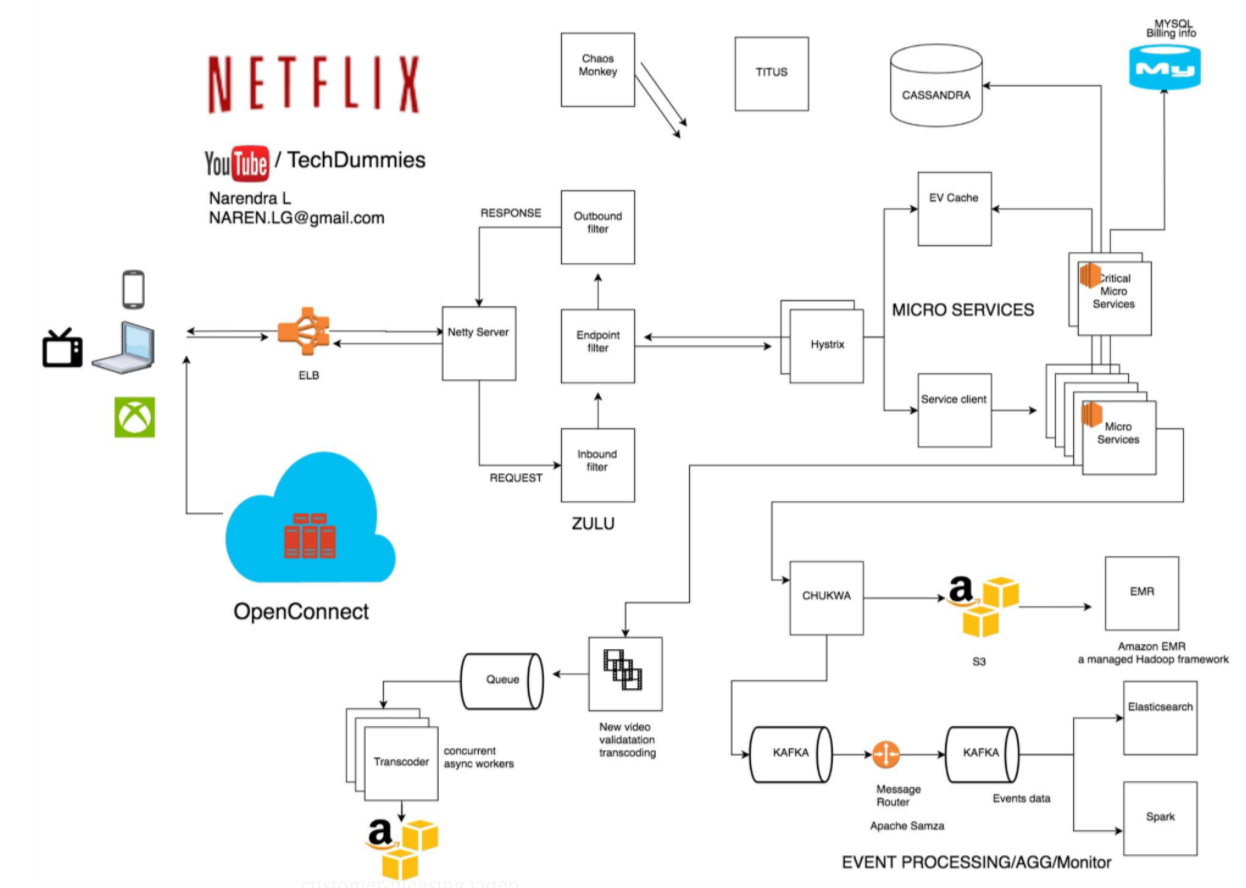
Rysunek 1 – diagram architektury Netflix’a [1]
Systemy rozproszone występują dzisiaj na każdym kroku i korzystamy z nich często nie wiedząc, że są one złożone z wielu komponentów programowych. Transparentność rozwiązań sprzyja doświadczeniom użytkownika, który może dzięki temu skorzystać z szybkiego i często niezawodnego systemu.
[1] https://elatov.github.io/2021/02/distributed-systems-design-netflix/

Ekologiczne centra danych – jak wybrać dostawcę IT dbającego o planetę?
Przewodnik dla firm poszukujących partnerów IT korzystających z energooszczędnych rozwiązań
Zielone IT

Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
AdministracjaInnowacja
Helm – czyli jak uprościć zarządzanie w Kubernetes?
Warto o tym wiedzieć! Czym jest Helm, jak go używać i jak ułatwia on korzystanie z klastra Kubernetes?
AdministracjaInnowacja