Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
 Autor:
Autor:Sieci neuronowe i ich trening zostały poruszone już jakiś czas temu na naszym blogu. Jeżeli nie zdążyliście się jeszcze zapoznać z tematem lub chcielibyście odświeżyć nieco swoją wiedzę, to zapraszamy do lektury naszych artykułów z tej serii.
W tekstach wspomniane zostało, że częstym problemem, spotykanym szczególnie przez niewielkie firmy ze względu na ograniczony budżet, jest kosztowność procesu treningu – zarówno w kwestii finansowej, jak i sprzętowej. Aby nauczyć sieci neuronowe w dużym modelu, konieczny jest albo dostęp do usługi chmurowej, do której wydelegowane mogą zostać obliczenia (co przy dużych architekturach modeli może wymagać wykupienia drogiego pakietu), albo posiadania fizycznie (on-premises) wydajnych obliczeniowo jednostek przetwarzania (zazwyczaj GPU – graphical processing unit, określane często mianem „karty graficznej”), których koszt również znacząco wzrósł w ciągu ostatnich paru lat.
Pierwsze pytanie, które może nasunąć się czytelnikowi, to: „Dlaczego sieć neuronową miałbym trenować na procesorze graficznym?”. Rzeczywiście, podejście takie na pierwszy rzut oka nie wydaje się intuicyjne – przecież jednostką, na której zazwyczaj wykonywane są obliczenia związane z działaniem sprzętu, jest procesor, CPU. Odpowiedź leży jednak w charakterze obliczeń wykonywanych na potrzeby uczenia takiej sieci – są to stosunkowo proste operacje, które mogą zostać w bezproblemowy sposób zrównoleglone (przynajmniej w obrębie wyliczania parametrów jednej warstwy modelu).
Podczas, gdy CPU ma przeważnie jedynie kilka rdzeni, przeznaczonych do szybkiego wykonywania równoległych obliczeń, ale mających dostęp do dużej (w porównaniu z rdzeniami GPU) pamięci podręcznej cache, to GPU wyposażone jest w znacznie więcej rdzeni, które mimo posiadania mniejszej mocy i rozmiaru pamięci podręcznej, są zazwyczaj wystarczające na potrzeby obliczeń wykorzystywanych w procesie uczenia. W końcu GPU, czyli procesory graficzne, mają za zadanie usprawnienie wyświetlania obrazów na ekranie – ich działanie polega na jednoczesnym obliczeniu wartości koloru dla kilku tysięcy pikseli, aby obraz pojawiał się i animował w sposób płynny. Wyznaczenie koloru pojedynczego piksela jest jednak zadaniem obliczeniowo prostym – stąd takie rozwiązanie architekturalne zastosowane zostało w „kartach graficznych”.
Wspomnieliśmy o tym, że CPU ma dostęp do większej pamięci podręcznej niż GPU. Teraz przybliżymy: co to za rodzaj pamięci, do czego jest wykorzystywana i jak ustrukturyzowana?
Celem pamięci cache jest ułatwienie oraz przyspieszenie dostępu jednostki przetwarzającej do często wykorzystywanych przez nią danych. Założenie jest proste – im częściej procesor potrzebuje dostępu do pewnych zasobów, tym krótszy powinien być czas dostępu do nich. Z tego względu, pamięć cache zorganizowana jest w poziomach, określanych zazwyczaj jako L1, L2, L3 (oraz, rzadko, L4). Im numer mniejszy, tym pamięć „bliżej” procesora, a jej rozmiar mniejszy. Na tym etapie warto wspomnieć, że w różnych opisach architektury komputerów spotkać można oznaczenia pamięci aż do L7 – określa się tak niekiedy warstwy pamięci RAM, a nawet pamięć dyskową. Zasada jednak jest niezmienna – im wyższy numer, tym dłuższy jest czas dostępu do danych niż w przypadku poprzednich warstw, a także – przeważnie – rozmiar pamięci większy.
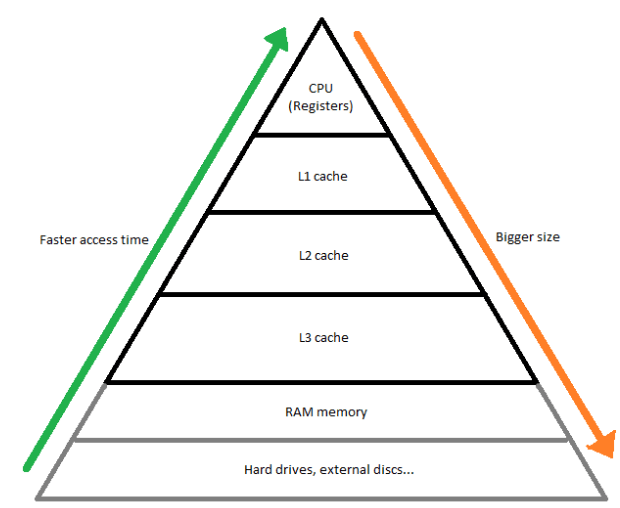
Rys. 1: Charakterystyka pamięci
Znając już charakterystykę GPU i CPU można wywnioskować, dlaczego główny procesor potrzebuje większej przestrzeni na dane szybkiego dostępu – jako, że wykonuje bardziej skomplikowane operacje, nierzadko konieczne jest zapamiętanie wyników operacji pośrednich, których może być sporo. Ponadto, CPU częściej rotuje zadania (aby uzyskać efekt „równoległego” wykonywania wielu zadań, a także obsługiwać wszelkiego typu przerwania sprzętowe, takie jak input użytkownika), a więc potrzebuje miejsca, w którym mogą zostać „na chwilę” odłożone obecnie wykonywane zadania, a za moment natychmiastowo podjęte z powrotem. W pamięci cache również przekazywane są instrukcje dla procesorów – a te trafiające do CPU są bardziej zróżnicowane i jest ich, zazwyczaj, więcej.
Poniżej porównanie poszczególnych właściwości CPU i GPU:
|
Aspekt |
CPU |
GPU |
|
Liczba rdzeni |
Kilka – kilkadziesiąt |
Kilka – kilkadziesiąt tysięcy |
|
Moc pojedynczego rdzenia |
Duża |
Mała |
|
Rozmiar pamięci cache |
3-4 poziomy, większy |
2-3 poziomy, mniejszy |
|
Poziomy pamięci dedykowane per rdzeń i wspólne |
Zazwyczaj rdzenie mają 3 dedykowane poziomy cache’a (osobne L1-L3 dla każdego rdzenia). |
Zazwyczaj rdzenie mają dedykowany tylko 1 poziom, reszta wspólna (tylko L1 osobne dla każdego rdzenia). |
|
Przykład zastosowania |
Operacje wymagające częstej zmiany kontekstu, skomplikowane pojedyncze obliczenia. |
Operacje mocno równoległe, niewymagające skomplikowanych obliczeń. |
Warto zauważyć, że trening sieci neuronowej można przeprowadzić z użyciem jedynie CPU – będzie on zazwyczaj jednak postępował kilkanaście, kilkadziesiąt, a czasem i kilkaset razy wolniej.
W tym miejscu warto zaznaczyć, że aby móc wydajnie wykorzystać możliwości oferowane przez procesory graficzne, należy trening odpowiednio skonfigurować. W przypadku GPU produkowanych przez firmę NVIDIA, oferowany jest framework CUDA, który (po instalacji) pozwala na ustawienie odpowiedniej konfiguracji sprzętowej. CUDA może być wykorzystywana z poziomu niektórych języków programowania, takich jak Python 3 czy C++, co znacząco ułatwia przygotowanie treningu w sposób optymalny. Ponadto, CUDA oferuje możliwość podzielenia treningu pomiędzy kilka GPU, aby uczenie naprawdę dużych modeli mogło odbywać się sprawniej.
A co w przypadku, kiedy model jest tak ogromny, że nawet nie da się go trenować w całości? Wówczas taką sieć możemy podzielić pomiędzy kilka węzłów obliczeniowych (zazwyczaj dzielenie odbywa się pomiędzy warstwami modelu) i ustalić zasady komunikacji między nimi – to jednak są już naprawdę skomplikowane zagadnienia, którymi większość firm nieukierunkowanych na rozwój sztucznej inteligencji jako swój główny cel nie będzie się musiała w najbliższym czasie przejmować.
Aby przyspieszyć znacząco trening złożonych sieci neuronowych, warto wykorzystać możliwości oferowane przez jednostki przetwarzania graficznego – choć nie były one tworzone w tym celu, to okazały się bardzo dużym ułatwieniem dla inżynierów uczenia maszynowego. Warto jednak dobrze pochylić się nad konfiguracją takiego treningu, aby zmaksymalizować zysk z wykorzystania droższych komponentów sprzętowych.
To już wszystko od nas na dziś! Zapraszamy już niedługo po więcej treści dotyczących uczenia maszynowego oraz tego jak trenować sieci neuronowe – przyjrzymy się, jak wykorzystać dostępną w internecie masę już wytrenowanych do przeróżnych, ogólnych celów modeli, aby usprawnić uczenie modelu pod nasz konkretny cel. Do zobaczenia!

Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
AdministracjaInnowacja
Helm – czyli jak uprościć zarządzanie w Kubernetes?
Warto o tym wiedzieć! Czym jest Helm, jak go używać i jak ułatwia on korzystanie z klastra Kubernetes?
AdministracjaInnowacja

INNOKREA na Greentech Festival 2025® – zdobyliśmy zielone serce Berlina!
Jak wygląda przyszłość zielonych technologii i jak nasza platforma wpisuje się w ideę recommerce? Relacjonujemy nasz udział w Greentech Festival w Berlinie – zobaczcie, co przywieźliśmy z tego inspirującego wydarzenia!
WydarzeniaZielone IT