✨Pozytywna energia i inspiracje po zeszłotygodniowym TechBBQ w Kopenhadze!
INNOKREA zna wiele twarzy grillowania😅. Klasyczna – towarzyska, z kiełbaskami, zimnym napojem i odwiecznym pytaniem: „czy już gotowe?”.
 Autor:
Autor:Tydzień temu w naszym cyklu ML udało nam się przybliżyć przebieg tego jak trenować sieci neuronowe – jakie ma fazy, jak należy dzielić zbiór danych i dlaczego powinno się bieżąco monitorować przebieg takiego treningu. Dziś chcemy odkryć przed Wami nieco więcej szczegółów – przeanalizujemy, co właściwie zachodzi w sieci neuronowej podczas jednej epoki treningu. Zapraszamy!
Na wstępie zaznaczyć trzeba jedno – choć generalna koncepcja treningu sieci neuronowych jest raczej jedna, to jej wariantów jest naprawdę wiele. Dzisiaj przeanalizujemy jeden z najprostszych – czyli poprawianie wag i biasów modelu każdorazowo po zaprezentowaniu jednej próbki z treningowej części zbioru (w literaturze to podejście określane jest jako stochastic gradient descent – SGD).
To powiedziawszy – czas przejść do rzeczy! Przeanalizujmy, jakie kroki zachodzą w modelu sieci neuronowej podczas jednej epoki treningu:
Kroki 1-4 określa się często jako forward pass / propagation (przejście w przód), natomiast kroki 5-6 jako backward pass / propagation (propagacja wsteczna).
Zauważmy, że kroki 1-3 to mechanizm taki sam, jak w przypadku predykcji na już gotowym modelu (przedstawiony 2 artykuły temu – jeżeli jeszcze nie mieliście okazji, to zachęcamy do zapoznania się!).
Warto tu zwrócić uwagę na jeszcze jedną rzecz, dotyczącą samej architektury sieci neuronowej: podczas, gdy tak zwane ukryte warstwy sieci mogą zawierać dowolną (w granicach rozsądku) liczbę neuronów – choć zazwyczaj przyjmuje się potęgi liczby 2 za dobry wyznacznik ich liczności – to jeżeli chodzi o warstwę wejściową oraz wejściową, obowiązują sztywne zasady:
Wróćmy zatem na chwilę do grafiki z jednego z poprzednich artykułów obecnego cyklu:
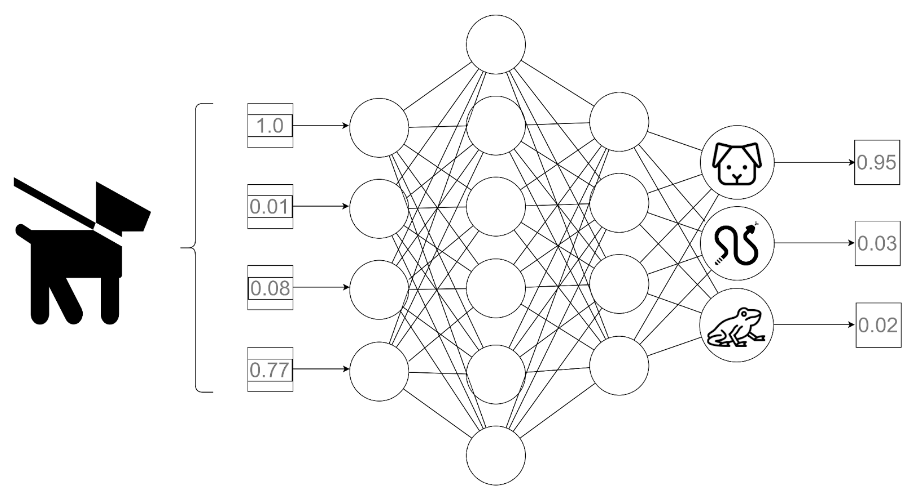
Rys. 1: Przykład działania forward pass prostej sieci
Przeanalizujmy pod lupą, co dokładnie dzieje się podczas forward pass na ukrytych warstwach:
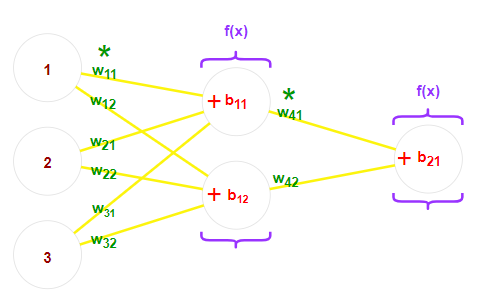
Rys. 2: „Szkolne” sieci neuronowe i ich parametry – uwagi oznaczono na zielono, biasy – czerwono, a funkcję aktywacji – fioletowo
Wartości zwracane przez neurony z warstwy wejściowej “podróżują” za pomocą połączeń do każdego z neuronów kolejnej warstwy. Każde połączenie ma wagę W, przez którą przetwarzana wartość jest mnożona.
Na wejściu do neuronu kolejnej warstwy, wszystkie wchodzące wartości pomnożone przez właściwe wagi są sumowane. Do tej sumy dodaje się także wartość biasu B konkretnego neurona.
Powstała w tej sposób suma przekazywana jest do funkcji aktywacji A. Zadaniem takiej funkcji jest przełamanie liniowości wykonywanych operacji. Co to oznacza?
Zauważmy, że dotychczas wykonywane operacje (mnożenie oraz dodawanie) modyfikowały wartości wejścia w sposób liniowy. Gdybyśmy kontynuowali jedynie takie traktowanie danych, to każda kolejna warstwa byłaby przekształceniem liniowym wyniku warstwy poprzedniej – który też przecież powstał w wyniku operacji liniowych! Matematyka nie pozostawia złudzeń w tym zakresie – złożenie funkcji liniowych, niezależnie od ich liczby – jest również tylko funkcją liniową! Oznacza to, że bez wprowadzania funkcji aktywacji, które burzą liniowość naszej struktury – cała, wielka sieć neuronowa mogłaby tak naprawdę zostać zastąpiona… Jedną funkcją postaci f(x) = ax + b. A choć funkcje liniowe są – wbrew pozorom – potężnym narzędziem statystycznym, to jednak konstruowanie jej poprzez budowanie obszernych, sztucznych sieci neuronowych… Cóż, brzmi jak zbyt duży kaliber na to zadanie.
Po tej, dość szerokiej, dygresji – przybliżmy sobie, jak zazwyczaj wygląda taka funkcja aktywacji.
Funkcje aktywacji możemy podzielić na te dotyczące:
W pierwszym przypadku, jej celem jest wspomniane zaburzenie liniowości, w drugim natomiast – przekształcenie wyników w dziedzinę prawdopodobieństwa (co zazwyczaj oznacza przeskalowanie wartości do przedziału [0 ,1]).
Na warstwach ukrytych najpowszechniej stosowana jest funkcja ReLU:
f(x) = max(0, x).
Funkcja ta zachowuje zależność liniową dla wartości większych lub równych zeru, natomiast wszelkie wartości ujemne zaokrągla właśnie do niego.
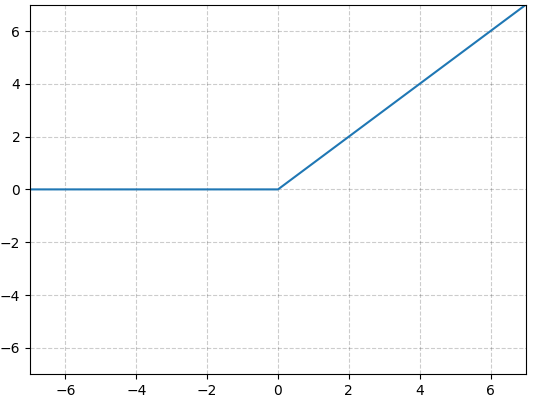
Rys. 3: Wykres funkcji ReLU
Na ostatniej warstwie, funkcję wybieramy w zależności od zadania:
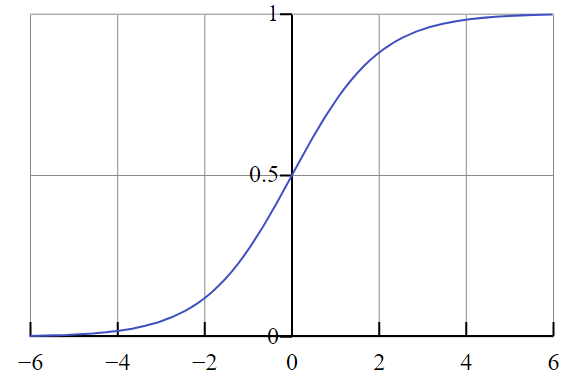
Rys. 4: Wykres funkcji sigmoid (źródło: Wikipedia.org)
Udało nam się uzyskać wyniki. Teraz pozostaje sprawdzić tylko – jak dalekie od prawdy one są?
W tym celu z pomocą przychodzi nam tzw. funkcja straty – pozwala ona określić, jak duży błąd popełniła nasza sieć, porównując uzyskane wyniki z prawdziwymi (tzw. ground truth). Często stosowane są tu funkcja zwane cross entropy lub categorical cross entropy. Od tego miejsca jednak nie będziemy wchodzić już w matematyczne szczegóły – jako, że wymagałoby to konkretnego przygotowania matematycznego, a artykuł ten jest raczej dość ogólnym wstępem
Ostatnim krokiem fazy dostosowywania parametrów w epoce jest właśnie propagacja wsteczna – obliczenie dla każdego parametru sieci pochodnej po wyliczonej funkcji straty, wyznaczającej, w którym kierunku i jak bardzo należałoby daną wagę lub bias poprawić, aby wynik był bliższy prawdzie. Po obliczeniu takiej wielowymiarowej pochodnej (gradientu) dla wszystkich trenowalnych parametrów sieci, ich wartości ulegają poprawie (jak gwałtownej? Zależy to od ustalonej wartości współczynnika uczenia, ang. learning rate).
To już wszystko na dziś! Do zobaczenia za tydzień, gdzie opowiemy o metodach przyspieszania i poprawiania treningu, a także dowiemy się, że żadna sieć nie jest nieomylna – nie może Was zabraknąć!

✨Pozytywna energia i inspiracje po zeszłotygodniowym TechBBQ w Kopenhadze!
INNOKREA zna wiele twarzy grillowania😅. Klasyczna – towarzyska, z kiełbaskami, zimnym napojem i odwiecznym pytaniem: „czy już gotowe?”.
InnowacjaSztuczna InteligencjaWydarzenia

Detekcja Obiektów w Computer Vision
Po fundamentach sieci neuronowych i klasyfikacji obrazów, czas zagłębić się w detekcję obiektów. Czym dokładnie jest? Jak różni się od prostego przypisywania etykiety całemu obrazowi? W tym artykule nie tylko odpowiemy na te pytania, ale także przyjrzymy się praktycznemu zastosowaniu popularnego algorytmu YOLO.
InnowacjaSztuczna Inteligencja

TNW Amsterdam 2025® oczami CEO: przyszłość innowacyjnych technologii
🔥 Gorące wieści z Amsterdamu! Innowacje, mnóstwo dobrych rozmów... i wspomnienie o milczącym barmanie.🤷♂️💡
Sztuczna InteligencjaWydarzenia