10 korzyści z dedykowanego oprogramowania dla Twojej firmy – mniej zasobów, większa wydajność
Dedykowane oprogramowanie to inwestycja, która zwiększa wydajność firmy, minimalizując zużycie zasobów IT i wspierając strategię zrównoważonego rozwoju.
 Autor:
Autor:Dziś chcielibyśmy zabrać Was już nieco… głębiej – złapiemy więc perspektywę na deep learning, czyli sztuczne sieci neuronowe – zapraszamy!
W internecie dostępne są niezliczone artykuły dotyczące budowy, działania oraz treningu sieci neuronowych. Ich autorzy, zazwyczaj w sposób bardzo rzetelny i szczegółowy, chcą wprowadzić nas we wszystkie tajniki tych specyficznych struktur przetwarzania danych – a jest ich całkiem sporo, zwłaszcza, jeżeli to pierwszy raz, kiedy zmierzamy się z tym tematem. Rezultat? Przestajemy czytać artykuł w połowie, zniechęcamy twierdząc, że “to chyba nie dla mnie…”, a do tematu ponownie podejdziemy kiedy wystarczająco czasu, by zapomnieć o poprzednim niepowodzeniu (o ile w ogóle!). Nic dziwnego, w końcu sformułowania “reguła łańcuchowa” czy “wyliczanie gradientu po funkcji L” wraz z obszernymi kalkulacjami i wzorami potrafią skutecznie zniechęcić niewtajemniczonego czytelnika – szczególnie, jeżeli to jego pierwsze starcie z tematem sztucznych sieci neuronowych!
Skoro udało nam się już ustalić za jak złożony temat zamierzamy się brać, to teraz przychodzi pora na ustalenie planu działania, który pozwoliłby nam oswoić się z tym nietrywialnym zagadnieniem.
Zapoznawanie zaczniemy od… końca. Na początek przede wszystkim należy określić do czego (w podstawowym scenariuszu) takie sieci są wykorzystywane oraz jak wygląda działanie takiego gotowego już modelu?
Choć sieci neuronowe występują w wielu wariantach, my skupimy się dziś na tym najbardziej podstawowym FCNN (ang. fully-connected neural network) wykorzystywanym do klasyfikacji, czyli przyporządkowania próbce danych konkretnej kategorii wynikowej. Jest to rodzaj sieci przyjmujący na wejściu wektor liczb, a zwracający prawdopodobieństwa przynależności próbki danych do każdej z dostępnych klas.
Przykładowo: dla danych wejściowych opisujących (w sposób numeryczny) cechy konkretnego zwierzęcia i dostępnych klas: ssak – gad – płaz, danymi wyjściowymi sieci byłoby prawdopodobieństwo przynależności opisanego organizmu do każdej z dostępnych kategorii. Naturalnie, jako ostateczny wynik uznalibyśmy tę klasę, której prawdopodobieństwo uznane zostało za najwyższe.
Opisana powyżej procedura przyporządkowywania klasy konkretnej próbce przez gotowy model nazywana jest predykcją.
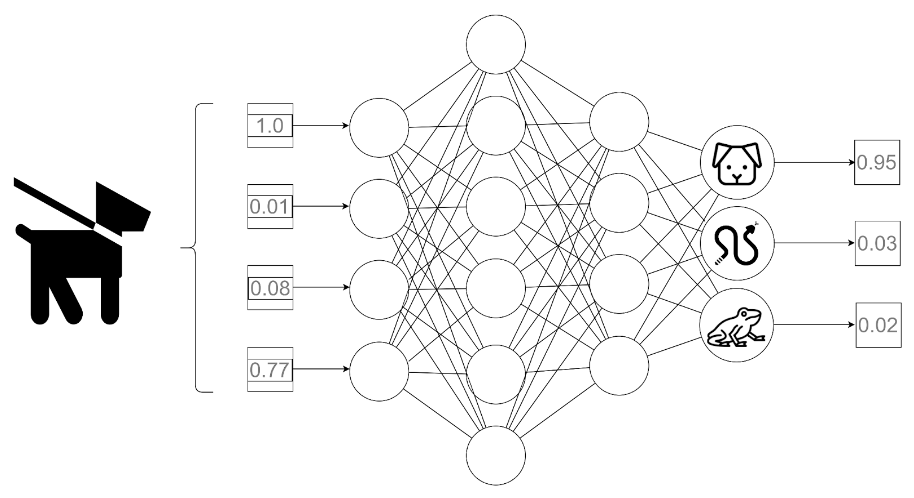
Rys. 1: Schematyczne przedstawienie procesu predykcji. Na wejściu do modelu przekazywany jest wektor cech psa w formacie numerycznym. Na wyjściu otrzymujemy prawdopodobieństwa przynależności próbki do konkretnych klas.
Znamy już zastosowanie FCNN, ale nadal nie przyjrzeliśmy się temu, w jaki sposób z podanego wektora danych uzyskujemy prawdopodobieństwa klas.
Sieci neuronowe myśleć przedstawiać jako ogromne, złożone funkcje matematyczne, w których zachodzi mnóstwo operacji liniowych (mnożenie, dodawanie) na zmianę z nieliniowymi.
O samej strukturze takiej sieci myśleć można jak o pewnych warstwach, na których znajdują się neurony – węzły obliczeniowe.
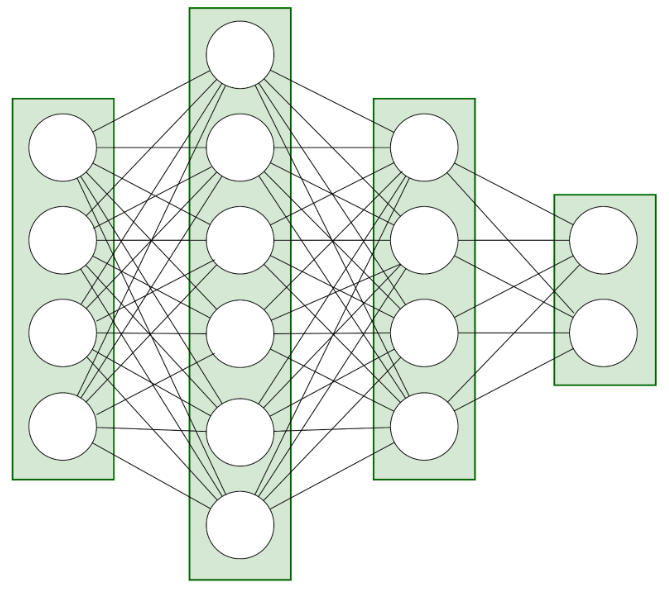
Rys.2: Struktura warstw sieci neuronowej – ta przykładowa sieć składa się z 4 warstw – wejściowej, wyjściowej i dwóch tzw. ukrytych
Każdy neuron definiuje pewien zestaw operacji:
Tak powstały wynik neurona będzie jednym z elementów przekazanych do kolejnej warstwy – a właściwie do każdego z neuronów kolejnej warstwy, na których cała opisana procedura się powtórzy.
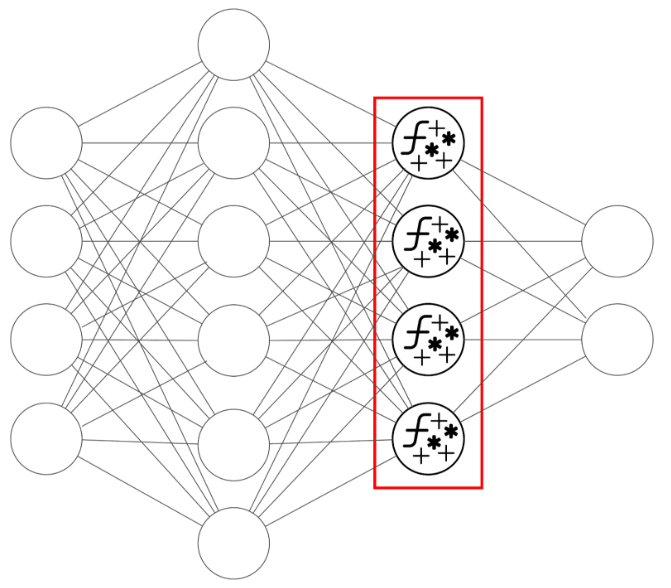
Rys. 3: Każdy neuron jest swego rodzaju węzłem obliczeniowym. Przyjmuje i składa tyle liczb, ile neuronów ma poprzednia warstwa (lub w przypadku pierwszej warstwy – tyle, ile elementów ma wektor wyjściowy), a zwraca jedną wartość, którą następnie przekaże każdemu neuronowi kolejnej warstwy.
Nawet bez szczególnie wnikliwej analizy pojąć można ogólny zarys działania takiej sieci, że każda z wartości wektora wejściowego poddana zostaje wielu następującym po sobie operacjom, a wynik każdej z tych operacji ma swoją wagę. Te wagi w niewytrenowanej sieci inicjowane są w sposób losowy, zatem wyniki również są losowe. W sieci wytrenowanej pod konkretne zadanie natomiast te wagi są już tak ustalone, aby sieć dawała na ostatniej z warstw jak najpewniejsze odpowiedzi (tzn. prawdopodobieństwo jednej, właściwej klasy bliskie 1, natomiast pozostałych klas – zbliżone do 0).
Przybliżyliśmy sobie dzisiaj temat predykcji w sieciach neuronowych – mamy już generalny ogląd na to, jak z wektora danych uzyskać można prawdopodobieństwa przynależności danej próbki do konkretnych klas. Za tydzień natomiast pochylimy się nad samym treningiem takiej sieci. Do zobaczenia!

10 korzyści z dedykowanego oprogramowania dla Twojej firmy – mniej zasobów, większa wydajność
Dedykowane oprogramowanie to inwestycja, która zwiększa wydajność firmy, minimalizując zużycie zasobów IT i wspierając strategię zrównoważonego rozwoju.
Zielone IT

Odpowiedzialne tworzenie oprogramowania: Jak zmniejszyć ślad węglowy aplikacji?
Praktyczne wskazówki jak programiści mogą aktywnie zmniejszyć emisję CO2 poprzez optymalizację kodu, infrastruktury i architektury aplikacji.
InnowacjaZielone IT

Zielone IT: Jak technologia może wspierać ochronę środowiska?
Wprowadzenie do idei zielonego IT (Green IT) – strategii, która łączy technologię z troską o planetę.
InnowacjaZielone IT