Zielona transformacja jako klucz do długoterminowego sukcesu
Zrównoważony rozwój jako strategiczna przewaga biznesowa. Dlaczego myślenie długoterminowe otwiera drzwi do większej konkurencyjności i nowych rynków.
 Autor:
Autor:Poprzednim artykułem rozpoczęliśmy bliższe przyglądanie się temu czym są sztuczne sieci neuronowe (ang. fully connected neural networks) – przybliżyliśmy nieco działanie wytrenowanego już modelu w zadaniach klasyfikacyjnych. Dziś pochylimy się nad zagadnieniem samego treningu – co to właściwie jest, jakie ma etapy i z czego każdy z nich się składa. Zapraszamy!
Klasyfikacja przy zastosowaniu sieci neuronowych jest przykładem uczenia nadzorowanego (a co to? Zachęcamy do zapoznania się z drugim artykułem cyklu ML, jeżeli jeszcze tego nie zrobiliście!). Zanim zatem podejdziemy w ogóle do treningu odpowiedniego modelu pod wybrane zadanie, konieczne jest posiadanie obszernego zbioru oznaczonych już danych: przykładowo, kontynuując zaproponowany w poprzedniej części artykułu problem rozpoznawania rodziny zwierząt ssak – gad – płaz, aby wytrenować odpowiedni model dla zadania, powinniśmy mieć np. po 5000 oznaczonych próbek reprezentujących każdą z rodzin.
Jeżeli uda nam się już zgromadzić taki zbiór danych, możemy go odpowiednio podzielić na 3 części:
i przystąpić do właściwej procedury treningu.
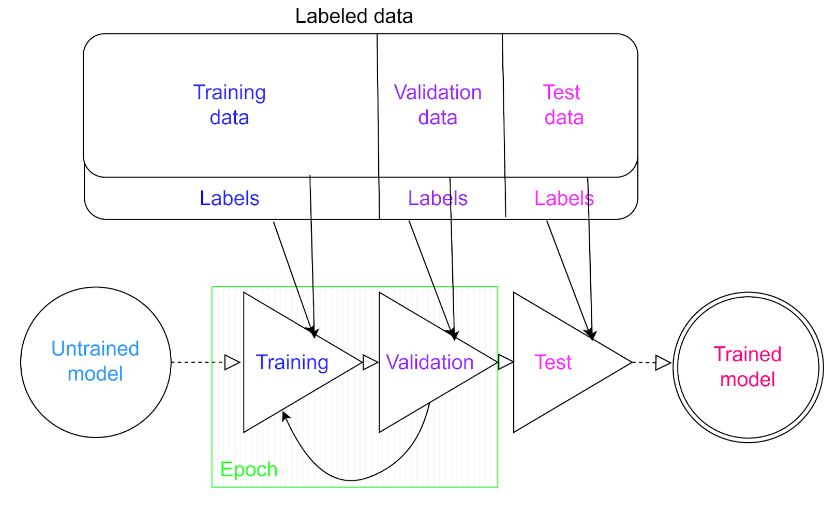
Rys. 1: Przykładowy schemat uczenia sztucznej sieci neuronowej. Źródło: Kurs ML 2023, Natalia Potrykus
Procedura treningu składa się z kilku kroków, wykonywanych w pętli:
Jedno powtórzenie kroków 1-2 nazywamy epoką (ang. epoch).
Po zakończeniu powyżej opisanego algorytmu przychodzi pora na użycie trzeciej części zbioru – części testowej. Używamy jej dokładnie tak samo, jak używaliśmy części walidacyjnej podczas każdej epoki – różnica jedynie jest w celu tego zastosowania. Zadaniem walidacji modelu (czyli kroku 2 z powyższej listy) jest sprawdzenie, jak model radzi sobie z “nieznanymi” danymi – czyli takimi, które nie brały udziału w samym dostosowywaniu wag. Tylko… po co?
Wyobraźmy sobie, że dysponujemy 1000 próbkami treningowymi, a liczbę epok treningu ustalamy z góry na wysoką jak na taką porcję danych – na przykład 500. Dodatkowo, mamy 150 próbek jako zbiór testowy – procedurę walidacji natomiast postanawiamy zupełnie pominąć.
I tak oto, obserwujemy wykresy z przebiegu treningu – widzimy wyraźnie, że z każdą epoką model jest coraz dokładniejszy w rozpoznawaniu klas próbek treningowych – pod koniec treningu uzyskujemy na tej części treningowej dokładność 99.99% – niemalże idealną!
Z zadowoleniem uruchamiamy więc test modelu… I tu następuje gorzkie rozczarowanie. Na naszych 150 próbkach testowych, które nie brały udziału w treningu, model uzyskuje dokładność rzędu 75%! Co się stało? Czy 500 epok to nadal było za mało?
Choć jest minimalna szansa, że to może być prawdą – cóż, raczej nie. To, co obserwujemy, to efekt tzw. przetrenowania modelu, czyli najzwyczajniej – nadmiernego dopasowania do danych treningowych. W rezultacie, model będzie bezbłędnie niemalże rozpoznawał dane użyte do treningu, jednak jego możliwości generalizacji będą słabe. Proces walidacji służy właśnie do tego, by rozpoznać moment, w którym model na nowych danych zaczyna sobie radzić coraz gorzej – i w tym miejscu przerwać trenowanie.
Dla powyższego przykładu – jeżeli jednak uruchomilibyśmy walidację, a wyniki zestawili na wykresie, to mogłoby to wyglądać następująco:
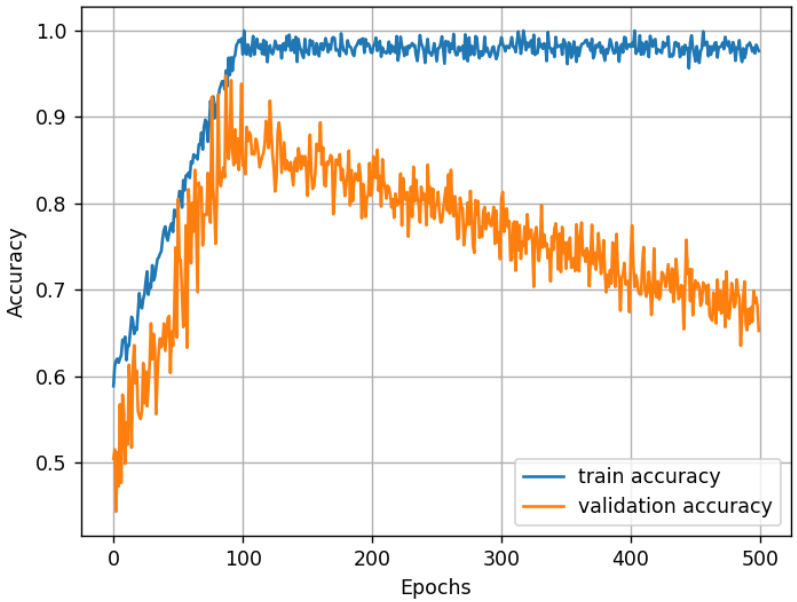
Rys. 2: Na niebiesko oznaczono dokładność (accuracy) modelu na zbiorze treningowym, natomiast na pomarańczowo – na zbiorze walidacyjnym. Z wykresu wyczytać można, że choć dokładność treningowa wydaje się niemal doskonała, to jednak po pewnym czasie model zaczyna mieć problemy z generalizacją.
Z tego zestawienia wyraźnie rozpoznać można, że około 100 epoki model zaczyna wykazywać oznaki przetrenowania – to byłby odpowiedni moment, by przerwać proces treningu!
Warto pamiętać, że choć rzadko uzyskamy na zbiorze testowym czy walidacyjnym tak dobrą dokładność jak na części treningowej, to odpowiednie monitorowanie przebiegu dostosowywania modelu może pozwolić nam wyciągnąć z niego jak najwięcej!
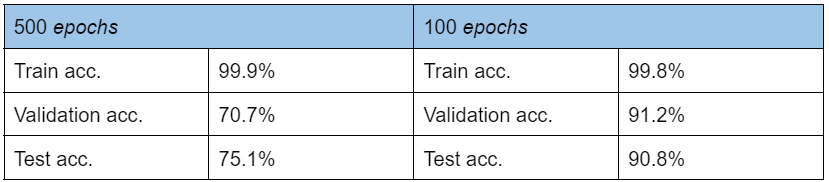
Tab. 1: Porównanie dokładności modelu na części treningowej, walidacyjnej oraz testowej dla 500 i 100 epok treningu
Morał z dzisiejszych rozważań jest prosty – w treningu, tak jak w życiu – niezbędny jest umiar! Na dzisiaj to wszystko od nas, słyszymy się za tydzień, kiedy to zejdziemy jeszcze głębiej i przyjrzymy się, jakie operacje zachodzą w samej strukturze sieci neuronowej podczas jednej epoki treningu. Do zobaczenia!

Zielona transformacja jako klucz do długoterminowego sukcesu
Zrównoważony rozwój jako strategiczna przewaga biznesowa. Dlaczego myślenie długoterminowe otwiera drzwi do większej konkurencyjności i nowych rynków.
Zielone IT

„AI dla lepszej przyszłości” – jak INNOKREA inspirowała podczas CEATEC Japan
To był mój pierwszy raz w Japonii. Spodziewałem się hałasu i nadmiaru technologii. Zamiast tego zobaczyłem spokojne twarze, precyzyjne rozmowy i cichą determinację.
InnowacjaSztuczna InteligencjaWydarzenia

INNOKREA na EDAG Smart Industry Summit, Fulda 2025 – i co to było za wydarzenie!
Już jadąc do Fuldy byliśmy w świetnych humorach😊, tak jakby wszystko miało pójść po naszej myśli. Samolot był super punktualny, bagaż dostaliśmy po kilku minutach czekania jako pierwsi pasażerowie
InnowacjaSztuczna InteligencjaWydarzenia