Zielona transformacja jako klucz do długoterminowego sukcesu
Zrównoważony rozwój jako strategiczna przewaga biznesowa. Dlaczego myślenie długoterminowe otwiera drzwi do większej konkurencyjności i nowych rynków.
 Autor:
Autor:W dzisiejszym artykule kontynuujemy temat uczenia maszynowego. Jeśli nie zapoznałeś się jeszcze z poprzednim naszym artykułem dotyczącym uczenia maszynowego, to zachęcamy. Dzisiaj dowiemy się nieco więcej o podejściach stosowanych w tej dziedzinie, ich zaletach i wadach, a także spojrzymy na możliwe zastosowania niektórych algorytmów.
Uczenie maszynowe jest szerokim zagadnieniem, w którym na chwilę obecną można wyznaczyć podział na cztery subdziedziny:
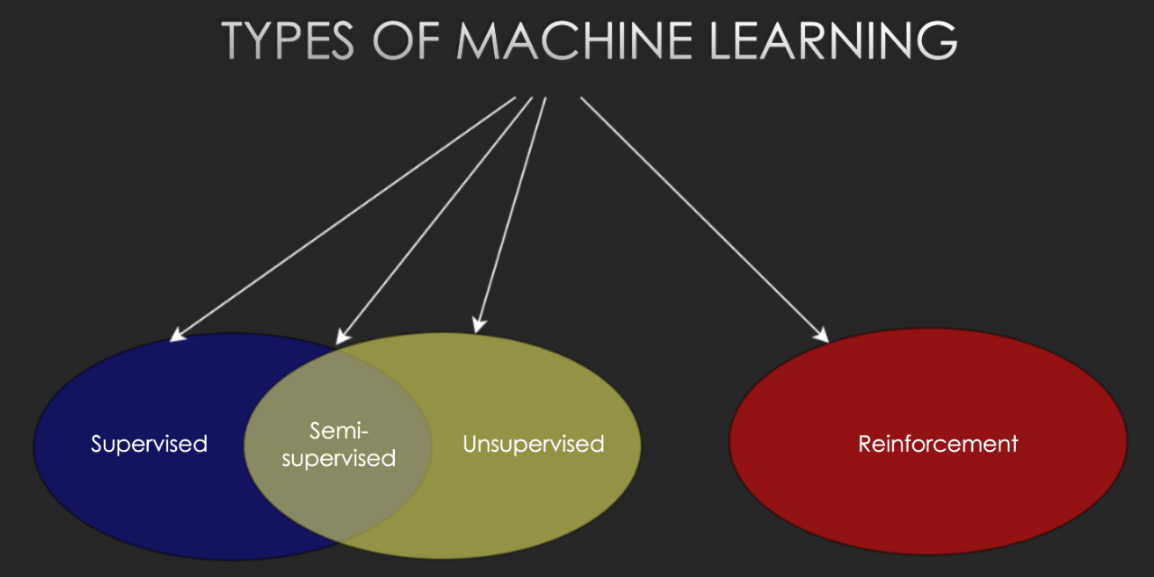
Rys. 1: Podział uczenia maszynowego na poddziedziny. Źródło: Kurs ML 2023, Natalia Potrykus
Jest to obecnie dziedzina szeroko wykorzystywana we wszelkich gałęziach przemysłu automatyzowanego, zalicza się do niej takie metody jak m.in.: tworzenie drzew decyzyjnych, czy sztuczne sieci neuronowe służące do rozpoznawania obiektów.
Jest to podejście mające bardzo szerokie zastosowanie we wszystkich sektorach przemysłowych i badawczych – jako, że daje możliwość dostosowania modelu pod konkretne, jasno zdefiniowane zadanie. Przykładowo:
Charakterystyką (a jednocześnie niekiedy i wielką wadą) uczenia nadzorowanego jest to, w jaki sposób trenuje się modele. Do dostosowania architetury pod konkretny problem potrzebne są duże zbiory oznaczonych danych. Oznacza to, że jeżeli chcemy uzyskać np. sieć rozpoznającą twarze na przekazanym obrazie, nie wystarczy trenować modelu na czystych zdjęciach, na których znajdują się ludzie – należy wprost wskazać, które obszary zdjęcia zostały uznane za ludzką twarz. Musimy najpierw przekazać sieci bardzo dużą liczbę (tysiące, dziesiątki tysięcy, a czasem i więcej) zdjęć z już oznaczonymi twarzami – czyli w tym przypadku dołączyć dodatkowy plik, który w określonym formacie przetrzymuje informacje o położeniu twarzy na obrazie (o sposobach zapisu takich danych powstać by mógł kolejny artykuł, na razie więc pominiemy zagłębianie się w takie szczegóły). Dopiero w ten sposób, przy odpowiednio dużej liczbie “nauczonych” obrazów, nasza sieć powinna być w stanie działać z powodzeniem.
Tę metodę treningu można przyrównać do naturalnego sposobu uczenia się przez dziecko – jeżeli na każdym spacerze rodzic będzie wskazywał i nazywał ptaki – różne gatunki, w różnych środowiskach i warunkach – to dziecko po pewnym czasie samo zacznie te zwierzęta rozpoznawać – mało tego, prawdopodobnie uwzglętni nawet gatunki, których nigdy wcześniej nie widziało, jeżeli rozpozna wystarczająco dużo cech, które do tej pory przypisywał ptakom.

Rys. 2: Przykładowy schemat uczenia sztucznej sieci neuronowej – nawet nie wchodząc jeszcze w szczegóły zauważyć można, że na każdym etapie treningu potrzebne są oznaczone dane. Źródło: Kurs ML 2023, Natalia Potrykus
Zastosowanie tej poddziedziny jest nieco mniej widoczne, ponieważ w przeciwieństwie do metod uczenia nadzorowanego tu zazwyczaj nie możemy określić konkretnego zadania dla modelu czy algorytmu – możemy natomiast uzyskać informacje o pewnych podobieństwach między danymi, wykonać jakieś grupowanie, wykryć anomalie (dane w jakiś sposób niepodobne do reszty zbioru), a niekiedy też spróbować uzupełnić brakujące dane w jakichś strukturach. Dla przykładu:
mamy pewien zbiór danych o konkretnym rodzaju kwiatów. Dla każdego z 1000 okazów opisane mamy:
Wiemy, że kwiaty te należą do 5 podgatunków, z których każdy charakteryzuje się nieco innymi parametrami (jeden z podgatunków zwyczajowo nie ma liści, ale ma długie płatki; drugi za to miewa liście, a do tego jego płatki są bardzo szerokie itd…).
Nie mamy żadnych dodatkowych informacji – nie wiemy, czy podział próbek według gatunków jest w zbiorze proporcjonalny, nie mamy też żadnych oznaczeń naszych danych – nadal jednak potrzebujemy przypisać nasze próbki do osobnych gatunków.
Od razu widać, że nie pomogą nam tu żadne metody uczenia nadzorowanego – w końcu nie mając żadnych oznaczonych danych nie jesteśmy w stanie wytrenować modelu!
W tym przypadku jednak z powodzeniem zastosować można grupowanie, zwane także klastrowaniem (ang. clustering), które jest jednym z najczęściej stosowanych podejść z zakresu uczenia nienadzorowanego. Klastrowanie polega na badaniu zależności danych między sobą, a następnie łączenie ich w pewne grupy (których liczbę zazwyczaj należy podać wprost) na postawie tych przeanalizowanych cech.
Wynik działania takich algorytmów (jak na przykład popularnej metody K-means, na podstawie działania której powstał poniższy wykres) przypisuje próbkom pewną etykietę – grupę – nadal nie odpowiada to na nasze pytanie o konkretny gatunek kwiata, ale mając dane już podzielone na 5 grup względem korelacji między nimi, problem staje się znacznie prostszy do rozwiązania – zamiast klasyfikować po kolei 1000 próbek, teraz wystarczy jedynie przyporządkować całym grupom odpowiednią nazwę biologiczną.
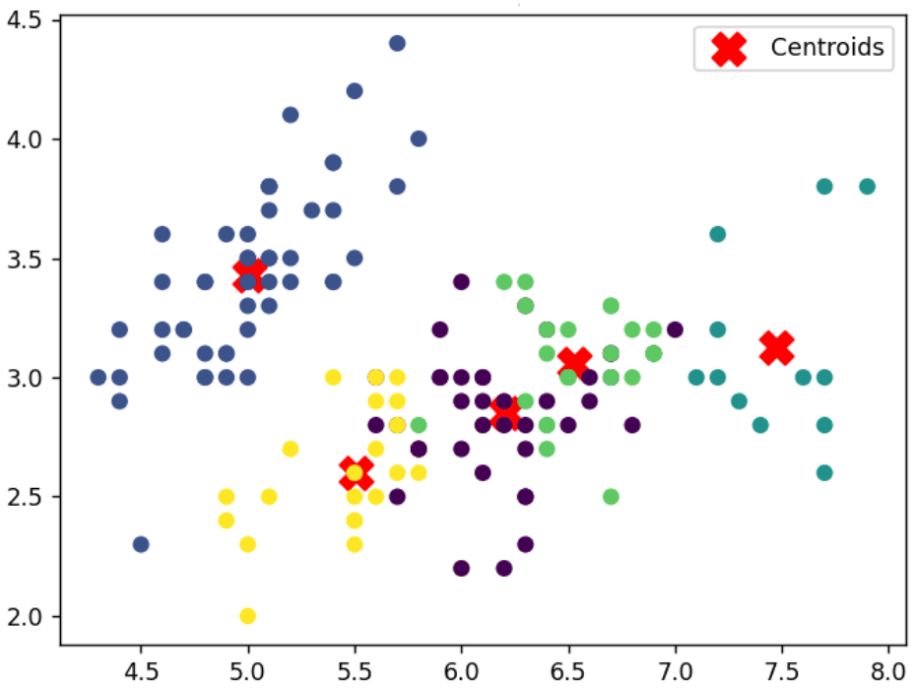
Rys. 3 – Wizualizacja działania algorytmu grupowania (wykres względem pierwszych dwóch wymiarów – długości i szerokości płatka). Źródło: Kurs ML 2023, Natalia Potrykus
Z pozoru podejście to wydaje się mieć bardziej ograniczone zastosowanie od omawianego poprzednika – dla wielu dziedzin będzie to prawdą. Z drugiej strony jednak, uczenie nadzorowane jest mocno ograniczone możliwością rozpoznawania znanych już obiektów, wzorów, zachowań. Przy podejściu nienadzorowanym natomiast takie ograniczenie nie występuje – dane mogą być na bieżąco analizowane, a odchylenia od normy z powodzeniem zauważane. Bardzo chętnie wykorzystuje to dziedzina cyberbezpieczeństwa – wrócimy do tego niebawem!
Jest to poniekąd próba pogodzenia dwóch powyższych podejść i połączenia je w jeden koncept korzystający z zalet obu z nich: możliwości wyznaczenia konkretnego celu dla modelu, jak i możliwość posiadania stosunkowo niewielu oznaczonych danych.
Podejście to zazwyczaj również nie zdaje egzaminu przy zbiorach niezbalansowanych – czyli takich, w których proporcje poszczególnych klas są zauważalnie nierówne. Bardzo duży wpływ na końcową jakość modelu ma również to, jak próbki już początkowo oznaczone są reprezentatywne względem całego zbioru danych – a często niemożliwe jest określenie tego z góry, przed próbami treningu. To wszystko wpływa na to, że podejście, choć daje szansę na znaczne ułatwienie procesu treningu (a co za tym idzie – obniżenie kosztów wytworzenia modelu), wiąże się też ze znacznie większą niepewnością co do jakości wynikowej sieci. Należy mieć to na uwadze, decydując się na zastosowanie tego podejścia – szczególnie w miejscach, gdzie algorytm działałby na danych krytycznych (przestrzeń wojskowa, medyczna), a także tam, gdzie niedokładne predykcje mogłyby wiązać się ze znacznymi kosztami dodatkowymi – bo w końcu jeżeli taki model miałby przynosić fabryce 20% więcej strat co roku w porównaniu z modelem, który wytrenowany byłby w sposób nadzorowany, to pewnie warto zainwestować na początku w bardziej kosztowne tworzenie sieci, potem jednak korzystać z niej ze znacznie większym powodzeniem.
Jest to poddziedzina, która – podobnie jak uczenie nadzorowane – wymaga danych, a także pewnych informacji o tych danych. Zazwyczaj jednak, zamiast mieć tu do czynienia ze statycznymi próbkami i ich etykietami, mierzymy się tu raczej z pewnymi sekwencjami – “ruchami” które agent może wykonać – oraz nagrodami, które otrzymuje za każdy z tych ruchów. Nagrody mogą być oczywiście dodatnie lub ujemne. Podczas treningu agent przegląda ogromne liczby ścieżek (sekwencji ruchów), a jego celem jest znalezienie tej o największej sumie nagród.
Takie podejście wykorzystywane jest w takich sytuacjach jak:
Oczywiście, aby móc w pełni wykorzystać potencjał wspomnianych algorytmów, potrzebne nam będzie zrozumienie, w jaki sposób najlepiej używać posiadanych danych oraz w jaki sposób są one przechowywane w komputerze – tym zajmiemy się już za tydzień. Zapraszamy!

Zielona transformacja jako klucz do długoterminowego sukcesu
Zrównoważony rozwój jako strategiczna przewaga biznesowa. Dlaczego myślenie długoterminowe otwiera drzwi do większej konkurencyjności i nowych rynków.
Zielone IT

„AI dla lepszej przyszłości” – jak INNOKREA inspirowała podczas CEATEC Japan
To był mój pierwszy raz w Japonii. Spodziewałem się hałasu i nadmiaru technologii. Zamiast tego zobaczyłem spokojne twarze, precyzyjne rozmowy i cichą determinację.
InnowacjaSztuczna InteligencjaWydarzenia

INNOKREA na EDAG Smart Industry Summit, Fulda 2025 – i co to było za wydarzenie!
Już jadąc do Fuldy byliśmy w świetnych humorach😊, tak jakby wszystko miało pójść po naszej myśli. Samolot był super punktualny, bagaż dostaliśmy po kilku minutach czekania jako pierwsi pasażerowie
InnowacjaSztuczna InteligencjaWydarzenia