Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
 Autor:
Autor:W poprzednim artykule zapoznaliśmy się z różnymi podejściami stosowanymi w uczeniu maszynowym do przetwarzania danych – nadal jednak nie wiemy, w jakiej formie takie dane mogą zostać przekazane do algorytmu? W końcu – to, co my odbieramy naszymi zmysłami jako obraz lub dźwięk, z perspektywy komputera jest jedynie ciągiem liczb! Dzisiaj zatem przedstawimy wam poszczególne szeroko stosowane metody reprezentacji danych – ta wiedza jest niezbędna do wyboru skutecznego algorytmu ich przetwarzania. Zapraszamy!
Standardowo, obrazy w przetwarzaniu maszynowym charakteryzują się następującymi własnościami:
Zazwyczaj architektury pozwalające na przetwarzanie obrazów wymagają, aby obraz taki był kwadratowy. Stosuje się w tym celu różne metody wyrównywania wymiarów, takie jak: wypełnianie marginesami, skalowanie do mniejszego wymiaru, rozciąganie.

Rys. 1: Wyrównywanie wymiarów obrazu
Wysokość i szerokość obrazu określa się w pikselach. Ostatni z parametrów przyjmuje natomiast zwyczajowo wartość:
Liczby oznaczające nasycenia tych barw przyjmują standardowo wartości 0-255 (co pozwala zapisać je binarnie na 1 bajcie).
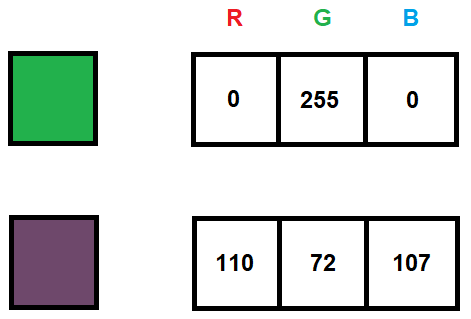
Rys. 2: Reprezentacja kolorów pojedynczego piksela na trzech kanałach w formacie RGB
Obrazy w skali szarości natomiast reprezentowane są przeważnie przy użyciu jednego kanału – tu wartości równieź są z przedziału 0 – 255. Liczba 0 oznacza czerń, natomiast 255 – biel.
Niekiedy może zaistnieć konieczność przedstawienia obrazu w skali szarości na trzech kanałach – wystarczy wówczas zapisać odpowiednią wartość z reprezentacji jednokanałowej na trzech kanałach.
Pliki audio w uczeniu maszynowym przetwarza się przeważnie na dwa sposoby: w formie “surowej” (ang. raw audio) jako wektor liczb, lub po przekształceniu zapisu sygnału na grafikę (tzw. spektrogram).
– Raw audio – jest wektor wartości amplitudy natężenia dźwięku w kolejnych odcinkach czasu. Odcinki te definiuje tzw. wartość sample rate (częstości próbkowania) – wskazuje ona, ile kolejnych wartości z wektora reprezentuje pomiary wykonane w ciągu jednej sekundy – przykładowo, jeżeli sample rate wynosi 48 kHz oznacza to, że jednej sekundzie zapisu odpowiada 48 000 kolejnych pomiarów z wektora.
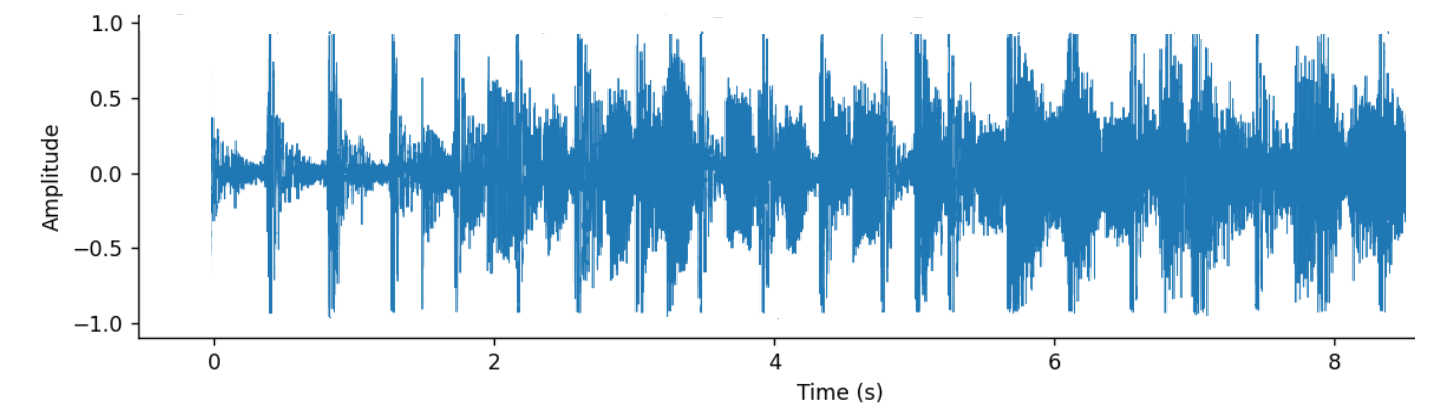
Rys. 3: Graficzna reprezentacja raw audio (fragment)
– Spektrogram – jest to obraz zawierający widmo dźwięku w czasie. Aby go uzyskać, stosuje się dyskretną transformację Fouriera (lub jej podobną) – do przekształcenia sygnału audio w dziedzinę częstotliwości. Następnie, tworzy się wykres mocy sygnału w różnych częstotliwościach od czasu.
W rezultacie uzyskujemy wykres, którego oś pozioma reprezentuje czas, oś pionowa częstotliwość, a kolor w danym obszarze wykresu oznacza moc dźwięku.
Spektrogram stworzyć można jeden dla całego pliku audio, można też taką próbkę podzielić na fragmenty (na przykład o określonej długości) i stworzyć takich spektrogramów klika. Tak przetworzone audio zazwyczaj analizuje się już przy użyciu takich samych algorytmów i narzędzi, jak w przypadku obrazu.
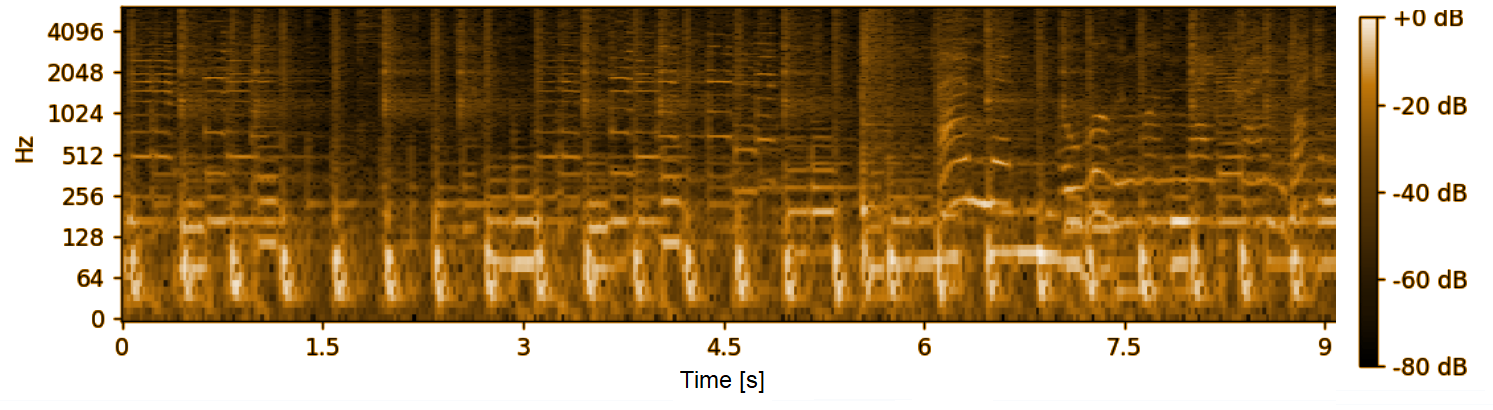
Rys. 4: Spektrogram pliku audio o długości 9 s.
Video to zasadniczo sekwencja obrazów, niekiedy ze skorelowanym dźwiękiem – do czynienia mamy zatem z dwoma modalnościami – danym dźwiękowymi (ang. audio) oraz wizualnymi (ang. visual). W algorytmach uczenia maszynowego obie z tych modalności przetwarzane będą osobno, a następnie wyniki uzyskane z obu ścieżek będą uwzględniane w określony dla konkretnego zadania sposób. Niekiedy też zupełnie pomija się jedną z modalności, skupiając się wyłącznie na analizie dźwięku, lub też przetworzeniu samego obrazu – takie rozwiązanie stosuje się w przypadku, kiedy audio albo obraz nie są szczególnie istotne (a może nawet niedostępne) lub dysponujemy ograniczonymi zasobami sprzętowymi.
Jeżeli chodzi o analizę samego obrazu w pliku audiowizualnym, to jest ona bardzo podobna do przetwarzania obrazu – z tym, że tutaj istotny jest też sposób, w jaki kolejne klatki następują po sobie. Ta sekwencyjność niesie ze sobą wiele informacji, zarówno dla ludzkiego oka, jak i algorytmu uczenia maszynowego – w końcu jeżeli pomieszalibyśmy klatki video, to znacznie trudniej byłoby nam zorientować się, czego dany film może dotyczyć! Dlatego też, celem zachowania sekwencyjności obrazów, podstawowy sposób przetwarzania danych wizualnych video opisać można następująco: obrazy zwyczajnie grupuje się po m kolejnych klatek – i tak, jak w przypadku pojedynczych obrazów za jedną próbkę treningową uznawało się jeden obraz, którego reprezentująca tablica ma 3 wymiary (wysokość, szerokość, liczba kanałów), tak tutaj m staje się czwartym wymiarem tablicy, a te m kolejnych obrazów zapisujemy w jednej próbce.
Przykładowo: jeżeli mamy video w rozdzielczości 1920 x 1080, zapisane w formacie RGB, a do analizy grupujemy po 10 klatek, to pojedyncza próbka, przetrzymująca informacje o tych dziesięciu następujących po sobie klatkach zapisana będzie w tablicy o wymiarach (1920, 1080, 3, 10).
Jeżeli chodzi o ścieżkę audio, to ta zazwyczaj przetwarzana jest zupełnie osobno – za pomocą sposobów opisanych powyżej.
Oczywiście, choć powyżej opisane zostały jedne z najpowszechniejszych sposobów reprezentacji danych, nie jest to w żadnym wypadku zakończona lista – w końcu rodzajów danych jest znacznie, znacznie więcej! Na szczęście, w przypadku większości podstawowych zadań z zakresu uczenia maszynowego, powyższe informacje powinny dać wystarczającą bazę, aby móc się z takowymi zmierzyć. Za tydzień zaczynamy temat związany z IOT – Internet Of Things, w którym uczenie maszynowe pojawia się w ramach choćby tak zwanego edge computing. Jeśli jesteście ciekawi, to zachęcamy do śledzenia naszego bloga!

Helm po raz drugi – czyli wersjonowanie i rollbacki dla Twojej aplikacji
Opisujemy jak wykonać aktualizację i rollback w Helm, jak elastycznie nadpisywać wartości oraz odkryjemy, czym są i jak działają szablony.
AdministracjaInnowacja
Helm – czyli jak uprościć zarządzanie w Kubernetes?
Warto o tym wiedzieć! Czym jest Helm, jak go używać i jak ułatwia on korzystanie z klastra Kubernetes?
AdministracjaInnowacja

INNOKREA na Greentech Festival 2025® – zdobyliśmy zielone serce Berlina!
Jak wygląda przyszłość zielonych technologii i jak nasza platforma wpisuje się w ideę recommerce? Relacjonujemy nasz udział w Greentech Festival w Berlinie – zobaczcie, co przywieźliśmy z tego inspirującego wydarzenia!
WydarzeniaZielone IT